Deep Learning
Foundations and frontiers of deep learning, neural network architectures, training techniques, loss functions, regularization, and modern advances.
37 posts
-
 LLM
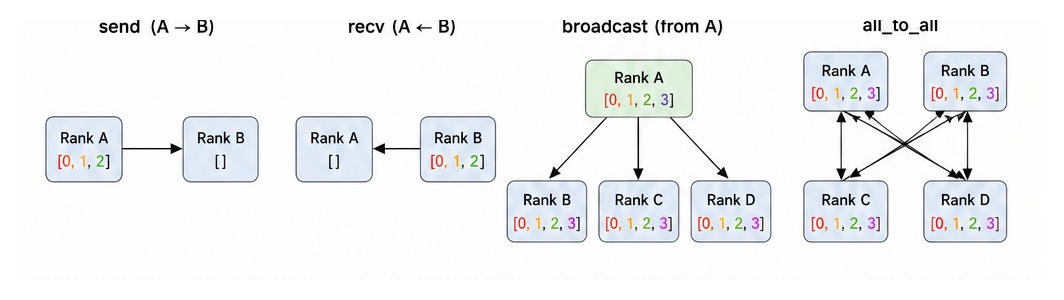
LLMDistributed Training: How to train Large Language Models (LLM)
Comprehensive guide to distributed training for LLMs covering data parallelism, model parallelism, tensor parallelism, ZeRO optimizer, FSDP, 3D parallelism, DeepSpeed with interactive visualization, code examples.
-
 LLM
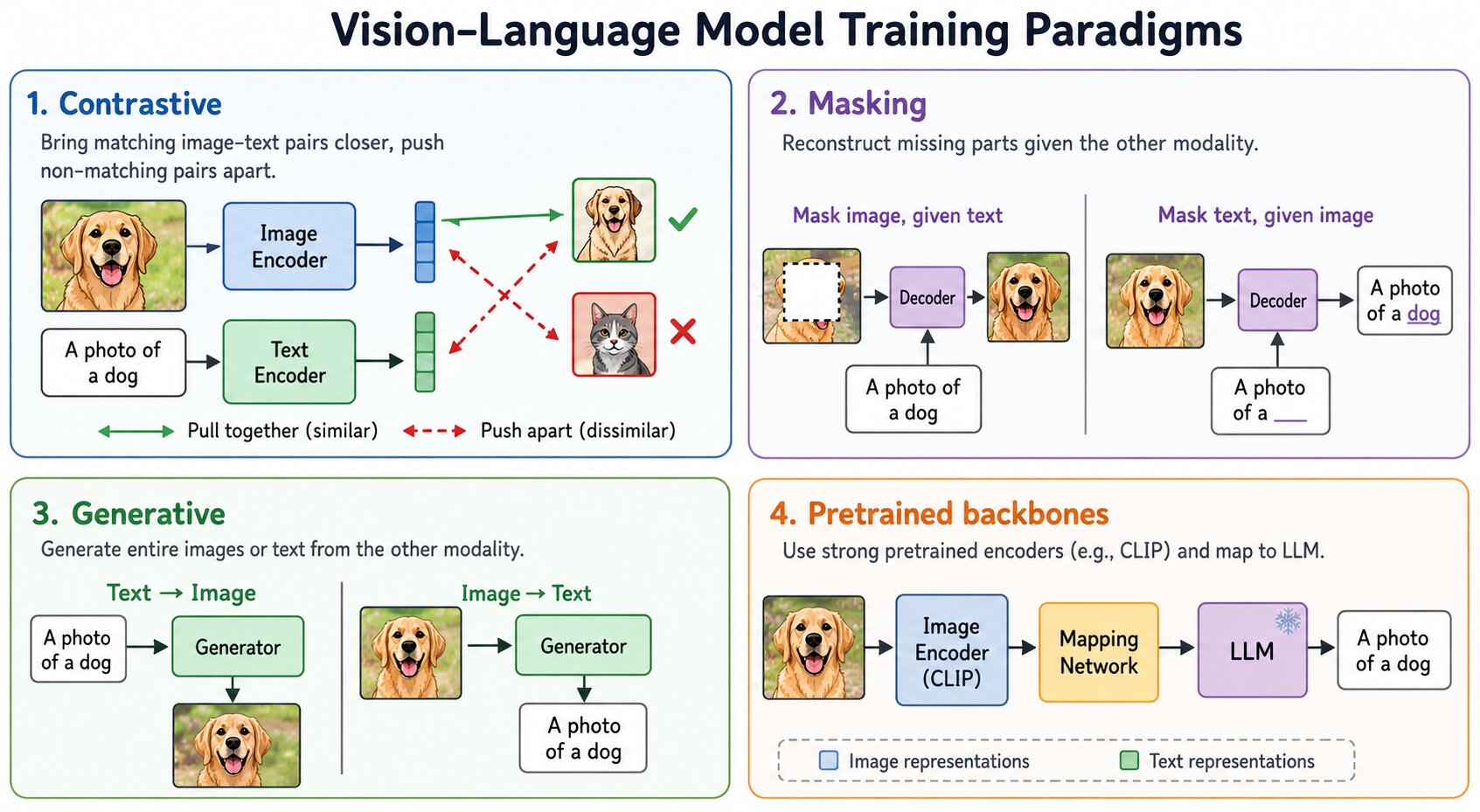
LLMVision Language Models (VLM)
Overview of Vision Language Models (VLMs) and their training paradigms: contrastive learning (CLIP), masking (FLAVA), generative approaches (CoCa, Chameleon), and pretrained backbone methods (Frozen, LLaVA, BLIP-2).
-
 CUDA
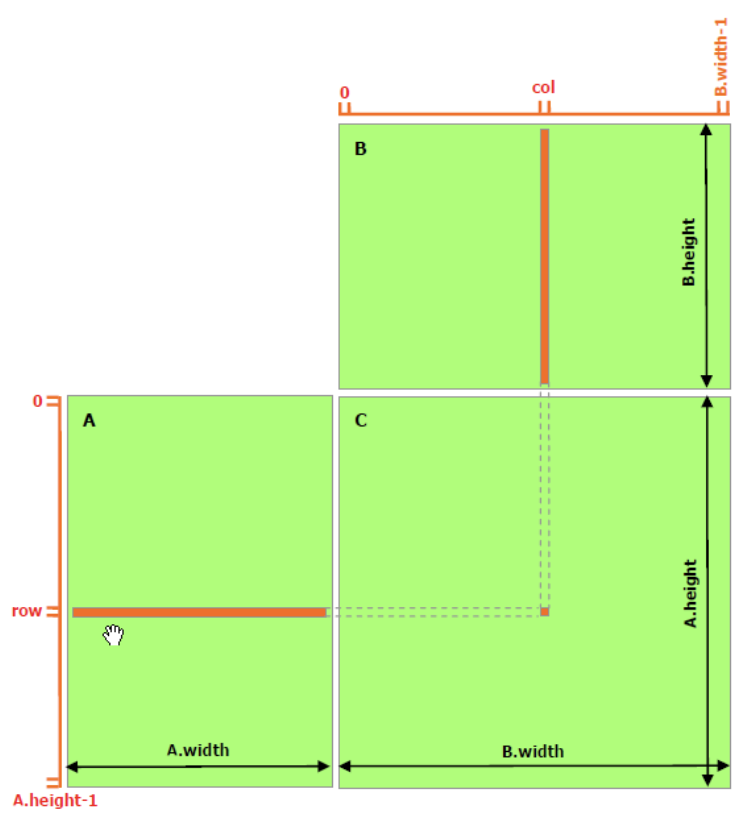
CUDAMatrix Multiplication in CUDA
Implementing matrix multiplication in CUDA from a naive CPU baseline to GPU-accelerated versions using tiled shared memory for deep learning workloads.
-
 Deep Learning
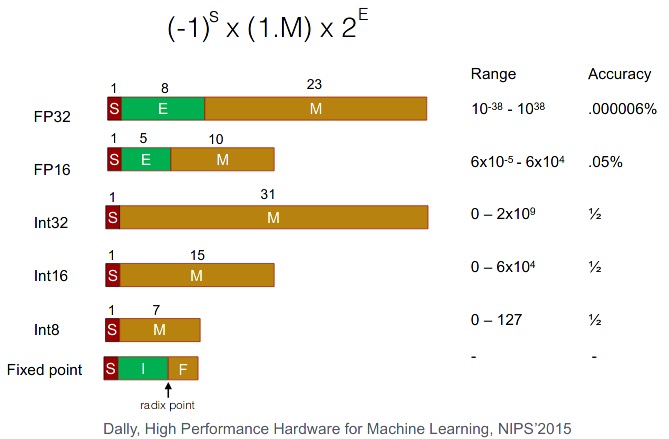
Deep LearningMixed Precision and Quantization: Accelerating Deep Learning Training and Inference
Comprehensive guide to mixed precision training (FP16/FP32) and INT8 quantization, covering GPU architecture, Tensor Cores, loss scaling, AMP, PTQ, QAT, and layer fusion with practical code examples.
-
 Computer Vision
Computer VisionPyTorch Basic Tutorial
A practical introduction to PyTorch covering tensors, autograd, neural network modules, and key libraries like torchvision and torchaudio.
-
 Deep Learning
Deep LearningIntroduction to Panoptic Segmentation: A Tutorial
Panoptic segmentation unifies semantic and instance segmentation assigning class labels and unique IDs to every pixel in an image.
-
 Deep Learning
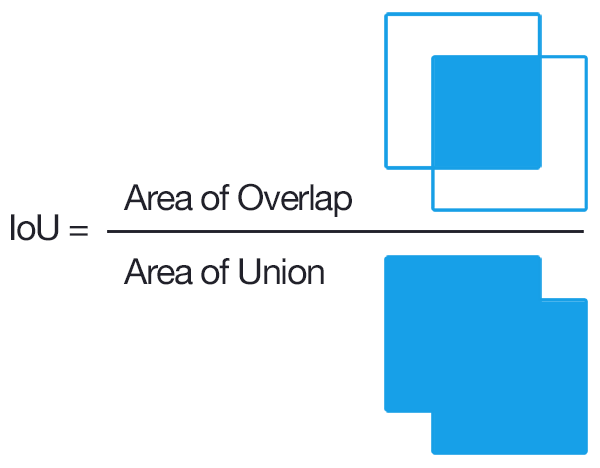
Deep LearningEvaluation metrics for object detection and segmentation: mAP
How IoU, precision-recall curves, and mean Average Precision (mAP) are used to evaluate object detection and segmentation models.
-
 Deep Learning
Deep LearningQuick intro to Instance segmentation: Mask R-CNN
Instance segmentation with Mask R-CNN: combining object detection and semantic segmentation to identify and segment each object instance separately.
-
 Deep Learning
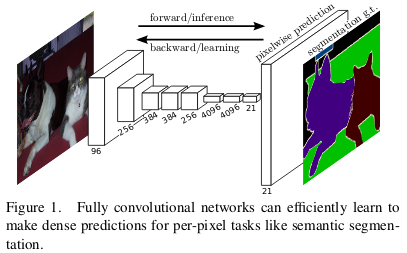
Deep LearningQuick intro to semantic segmentation: FCN, U-Net and DeepLab
An introduction to semantic segmentation, pixel-level classification using Fully Convolutional Networks, U-Net, and DeepLab architectures.
-
Deep Learning
Converting FC layers to CONV layers
How and why to replace fully connected layers with equivalent convolutional layers, enabling CNNs to accept arbitrary input sizes.
-
 Deep Learning
Deep LearningData augmentation
How data augmentation like flipping, rotation, color jittering artificially expands training data to build more generalizable deep learning models.
-
 Deep Learning
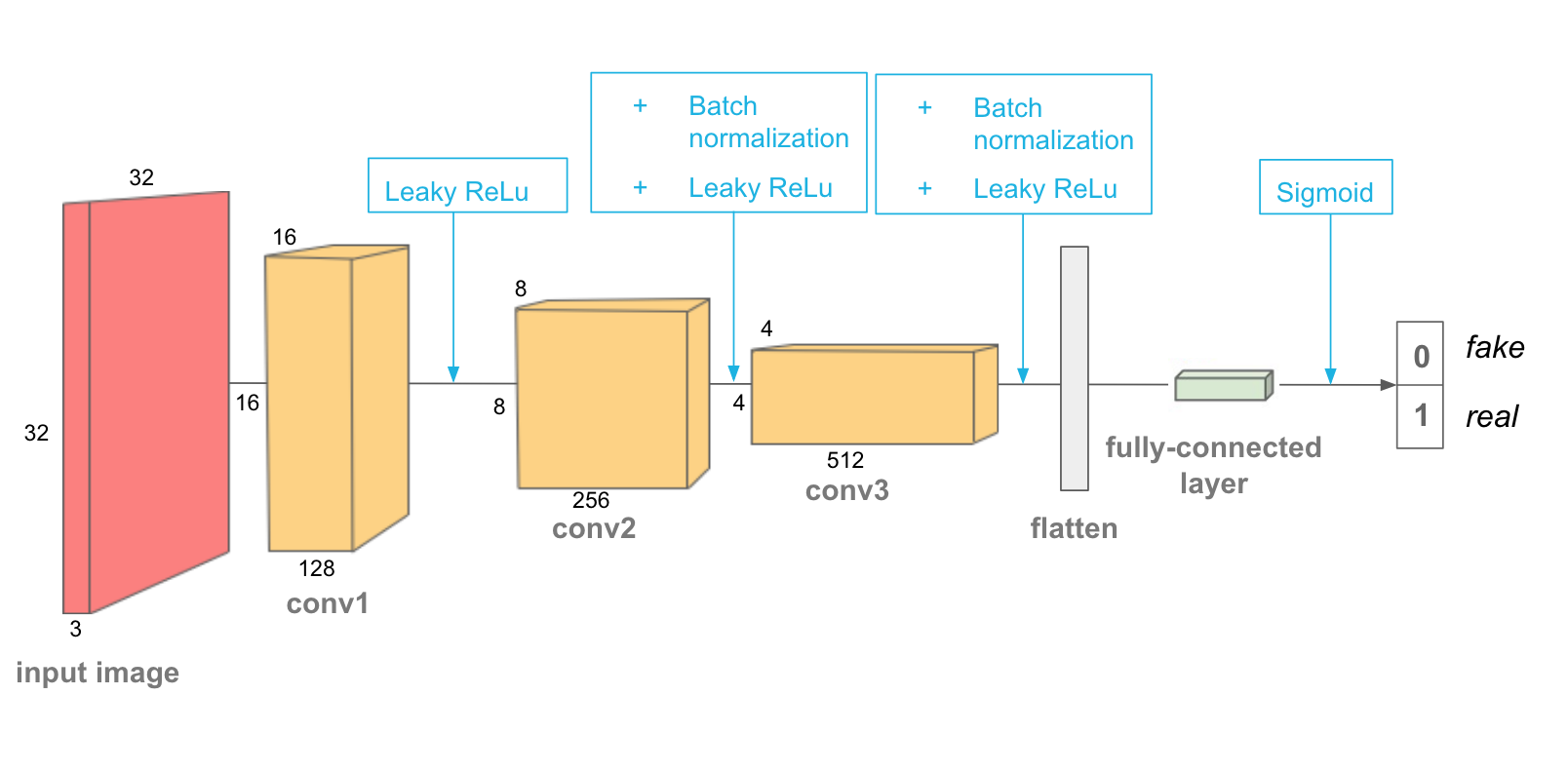
Deep LearningGenerative Adversarial Networks variants: DCGAN, Pix2pix, CycleGAN
An overview of GAN variants, DCGAN for image generation, Pix2pix for paired image translation, and CycleGAN for unpaired style transfer.
-
Deep Learning
Layer-specific learning rates
Why using different learning rates per layer in deep networks can compensate for vanishing gradients and improve transfer learning fine-tuning.
-
 Deep Learning
Deep LearningQuick intro to Object detection: R-CNN, YOLO, and SSD
A concise introduction to object detection methods, classification with localization, R-CNN family, YOLO, and SSD.
-
 Deep Learning
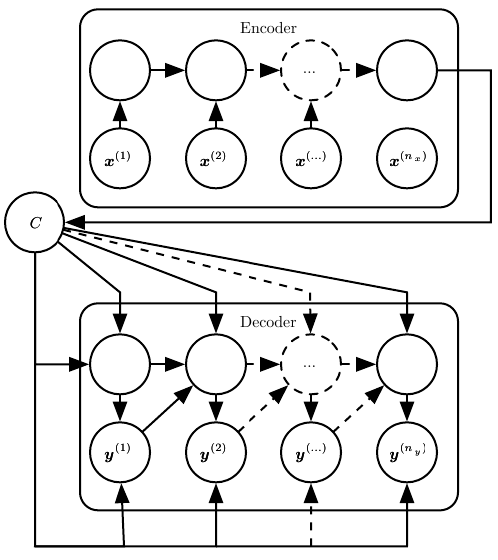
Deep LearningAttention
The attention mechanism in sequence-to-sequence models, how it allows the decoder to focus on relevant parts of the input at each step.
-
 Deep Learning
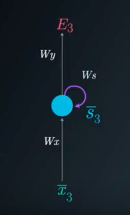
Deep LearningBackpropagation Through Time
A mathematical deep dive into how gradients are computed in RNNs via Backpropagation Through Time (BPTT), explaining vanishing gradient origins.
-
 Deep Learning
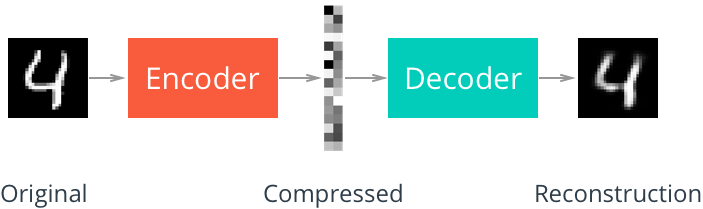
Deep LearningAutoencoder: Downsampling and Upsampling
How autoencoders learn compact data representations through an encoder-decoder architecture, covering downsampling and upsampling techniques.
-
 Deep Learning
Deep LearningWeight initialization in neural nets
Why proper weight initialization matters in deep learning: comparing zero, random, Xavier, and He initialization strategies.
-
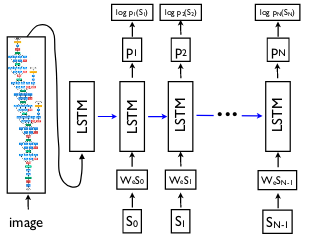 Deep Learning
Deep LearningImage captioning using encoder-decoder
Building an image captioning system using a CNN encoder and RNN decoder based on the Show and Tell architecture.
-
 Deep Learning
Deep LearningThe gradient problem in RNN
Why vanilla RNNs suffer from vanishing and exploding gradients, and how this limits their ability to capture long-range dependencies.
-
 Deep Learning
Deep LearningWhy Batch Normalization?
How batch normalization speeds up training by normalizing hidden layer activations across the network using learnable scale and shift parameters.
-
 Deep Learning
Deep LearningFilters in Convolutional Neural Networks
How convolutional filters detect spatial patterns and edges by responding to high-frequency changes in image pixel intensity.
-
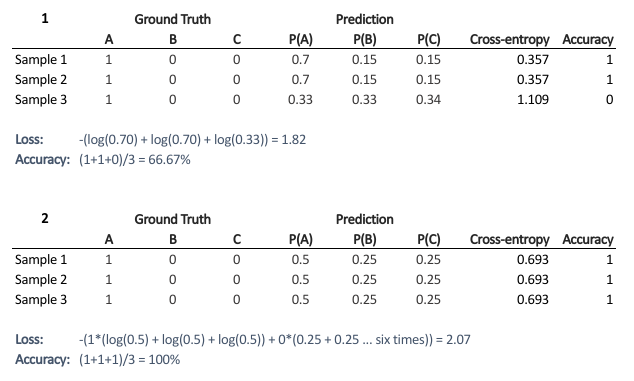 Deep Learning
Deep LearningLoss vs Accuracy
The distinction between loss (cross-entropy) and accuracy in neural network training, why they can diverge and what each metric tells you.
-
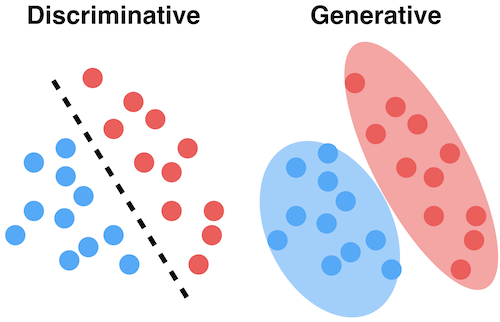 Deep Learning
Deep LearningGenerative models and Generative Adversarial Networks
An introduction to generative models and GANs, how a generator and discriminator compete to produce realistic synthetic data.
-
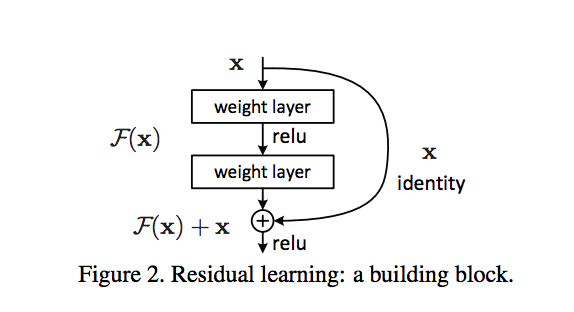 Deep Learning
Deep LearningSkip connections and Residual blocks
How ResNet's skip connections and residual blocks solve the degradation problem in very deep neural networks.
-
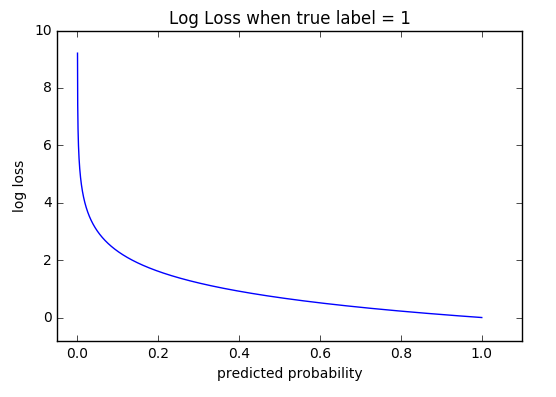 Data Science
Data ScienceLoss functions
A survey of common loss functions MSE, cross-entropy, hinge loss, with background on entropy, KL divergence, and the MLE connection.
-
 Data Science
Data ScienceOptimizers
An overview of neural network optimizers: SGD, momentum, RMSProp, and Adam, and how they improve on basic gradient descent.
-
Deep Learning
Transfer learning: How to build accurate models
Using pre-trained CNN models via feature extraction or fine-tuning to build accurate models when training data is limited.
-
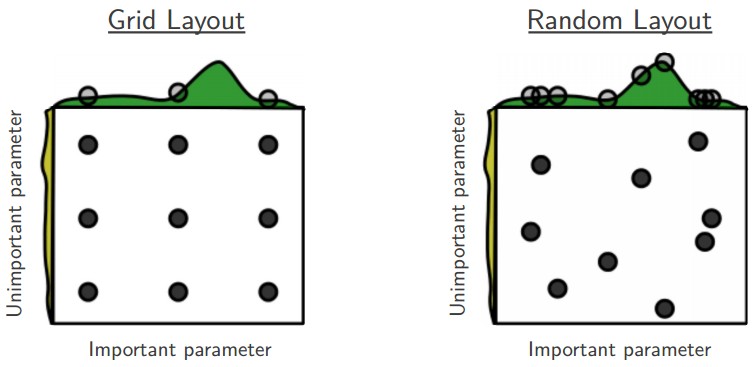 Data Science
Data ScienceMethods of Hyperparameter optimization
Comparing hyperparameter optimization strategies like grid search, random search, and Bayesian optimization with scikit-learn examples.
-
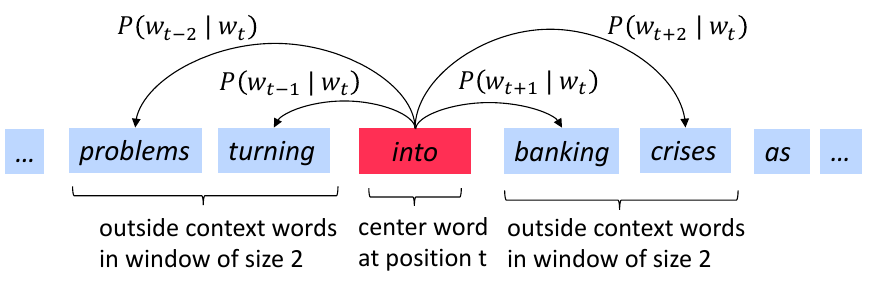 Deep Learning
Deep Learningword2vec: The foundation of NLP
How word2vec represents words as dense vectors by learning from context, solving the limitations of one-hot encoding for NLP tasks.
-
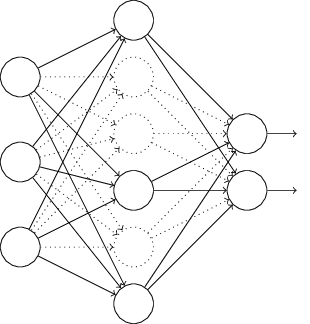 Data Science
Data ScienceDropout: Prevent overfitting
How dropout regularization prevents overfitting by randomly deactivating neurons during training, effectively ensembling many sub-networks.
-
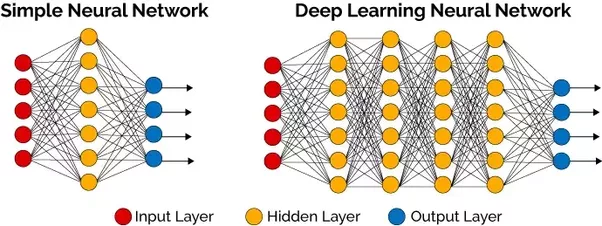 Data Science
Data ScienceHow deep should neural nets be?
Practical guidance on choosing neural network depth and layer sizes, input, hidden, and output layers for different problem types.
-
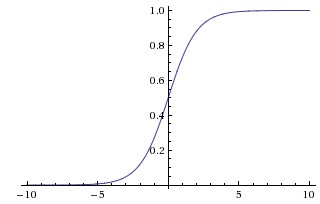 Data Science
Data ScienceDon't use sigmoid: Neural Nets
Why sigmoid activation functions should be avoided in deep neural networks, and what alternatives like ReLU offer instead.
-
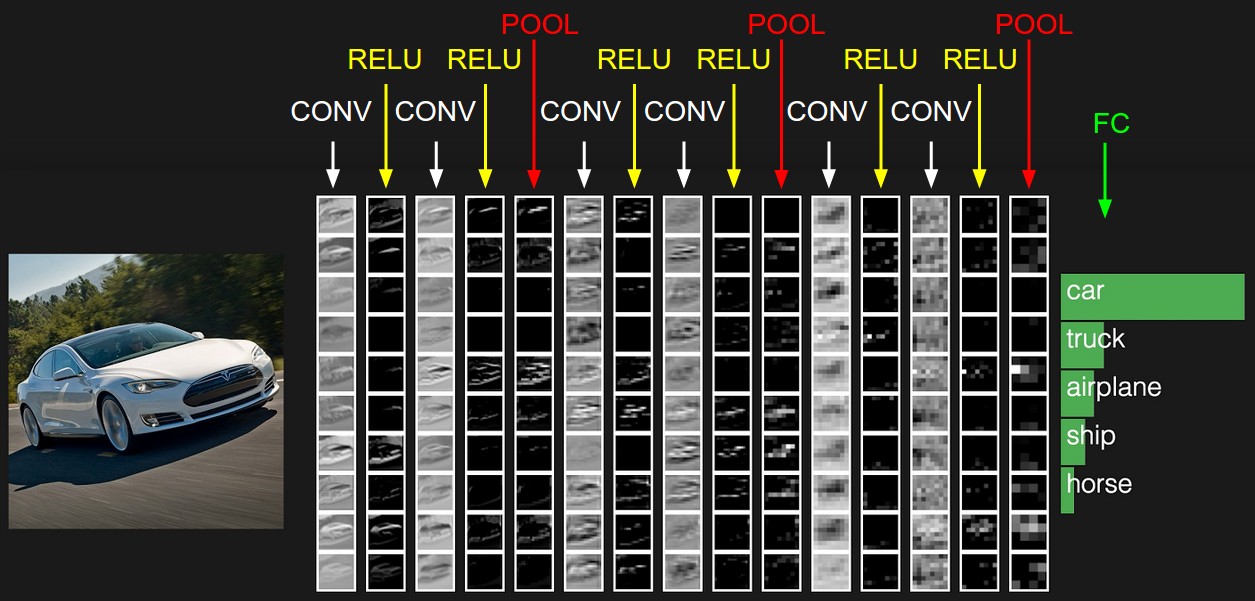 Deep Learning
Deep LearningThe magic behind ConvNets
How Convolutional Neural Networks work: convolutional, pooling, and fully connected layers, and how features are extracted from images.
-
Data Science
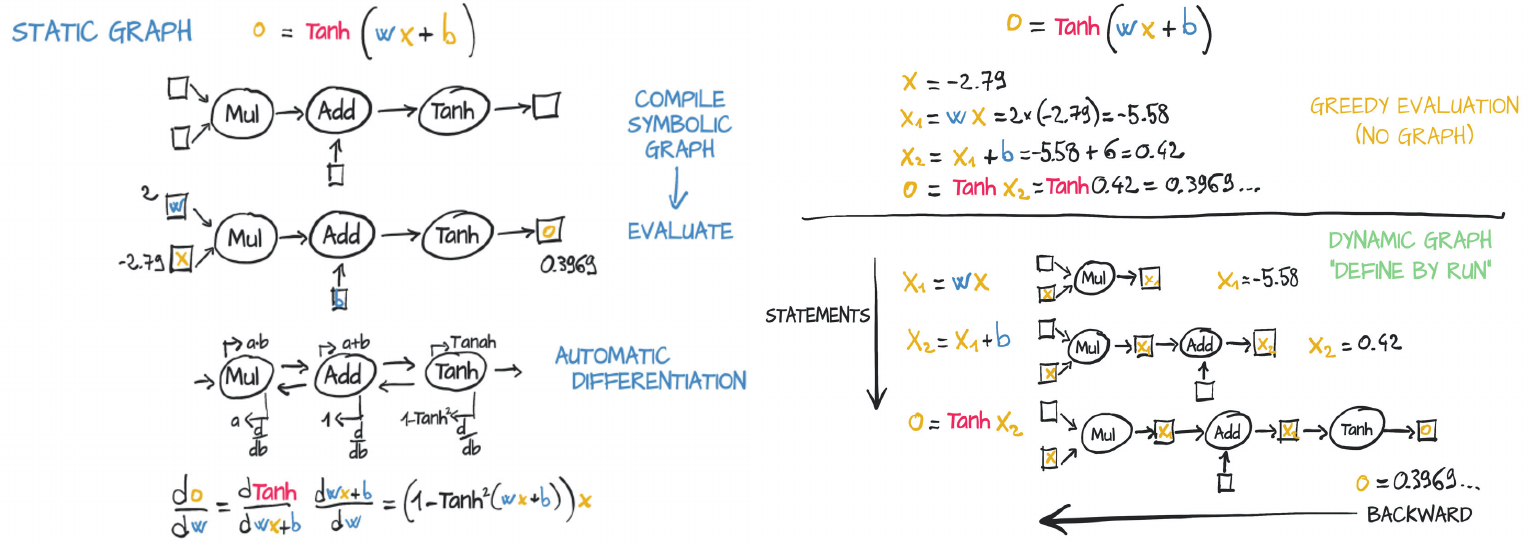
Computational graphs: Backpropagation
Backpropagation explained via computational graphs, a local, chain-rule-based method for computing gradients efficiently in neural networks.
-
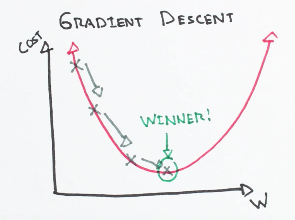 Data Science
Data ScienceGradient descent: The core of neural networks
How gradient descent works to optimize neural network weights by following the steepest direction of the loss function.
-
 Data Science
Data ScienceLinear algebra: The essence behind deep learning
How linear algebra underpins deep learning from score functions and weight matrices to image classification with neural networks.