Dropout is a regularization technique that prevents neural networks from overfitting. Regularization methods like L2 and L1 reduce overfitting by modifying the cost function. Dropout, on the other hand, modify the network itself.
Deep neural networks contain multiple non-linear hidden layers which allow them to learn complex functions. But, if training data is not enough, the model might overfit. We use regularization techniques to reduce overfitting.
How Dropout Works
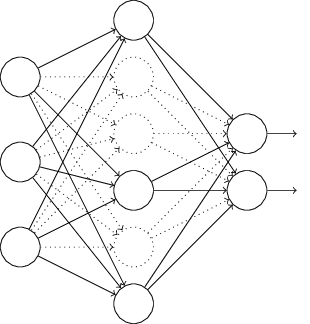
What dropout regularization does is to randomly drop neurons (along with their connections) from the neural network during training in each iteration. When we drop different sets of neurons, it’s equivalent to training different neural networks (as in ensemble methods). So, the dropout procedure is like averaging the effects of large number of different networks. The different networks will overfit in different ways, so the net effect of dropout will be to reduce overfitting. Also, these networks all share weights i.e. we aren’t optimizing weights separately for these networks. (tip: so basically every network gets trained very rarely.) But, it works. It serves its purpose of regularization.
In dropout, the network can’t rely on one feature but will rather have to learn robust features that are useful.
The dropout regularization was introduced in 2014. The authors improved the classification accuracy on MNIST dataset by 0.4% using combination of dropout L2 regularization. The dropout regularization has proved to be successful in reducing overfitting in many problems.
Multi-Head Attention as Regularization
In the Transformer architecture, having multiple attention heads introduces a form of regularization, as the model is encouraged to learn diverse representations. Each attention head may focus on different parts of the input sequence, capturing different aspects and dependencies. The outputs of multiple attention heads can be seen as an ensemble of models, helping to prevent overfitting in a manner similar to dropout.
References:
- Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov, “Dropout: A Simple Way to Prevent Neural Networks from Overfitting”, Journal of Machine Learning Research, 2014.
Comments