Most of us have our favourite machine learning algorithms. For some, it may be state-of-the-art algos like Support Vector Machines while for others it may be something simple like Naive Bayes.
But the truth is that the performance of these algorithms vary from problem to problem. For some applications, it may be good to use random forest while for others, logistic regression might be the optimal choice.
What Are Ensembles?
What if instead of using a single algorithm, we use multiple ones together? Is it even possible? Yes, it is. random forest does that. It is called model ensembles.
Bagging
In the simplest technique called bagging (Bootstrap Aggregating), we generate m training sets by sampling with replacement from the original data, each bootstrap set contains approximately 63.2% unique observations, then build a separate prediction model using each training set, and average (regression) or majority vote (classification) the resulting predictions. Bagging is a variance reduction technique.
Random Forest
Random forest provides an improvement over bagged trees. While building a number of decision trees, each time a split in a tree is considered, a random sample of m (< p) predictors is chosen from the full set of p predictors, this is called feature bagging. This decorrelates the trees, making the forest robust to noise. Random forest differs from bagging in the choice of predictor subset size m.
Boosting
In boosting, decision trees are built sequentially i.e. each tree is grown using information from previously grown trees unlike in bagging where we create multiple copies of original training data and fit separate decision tree on each. In boosting, sample weights are initialized uniformly and increased for misclassified samples at each step, forcing the next tree to focus on hard cases. Boosting is a bias reduction technique, it can convert weak learners into strong ones, but is more prone to overfitting than bagging or random forest.
Stacking
In stacking, the outputs of individual classifiers become the inputs of a higher-level learner (meta-model) that figures out how best to combine them. The base models and the meta-model do not have to be the same type of algorithm.
Ensembles can be constructed in several ways: using K-identical base learners trained on different data, K-different learners on the same data, K-different data folds, or K-different random seeds.
Decision trees, the building block of these ensemble methods, split nodes using criteria such as Gini impurity (choose feature with minimum Gini), Information Gain (based on entropy), or Variance Reduction (minimize RSS for regression trees).
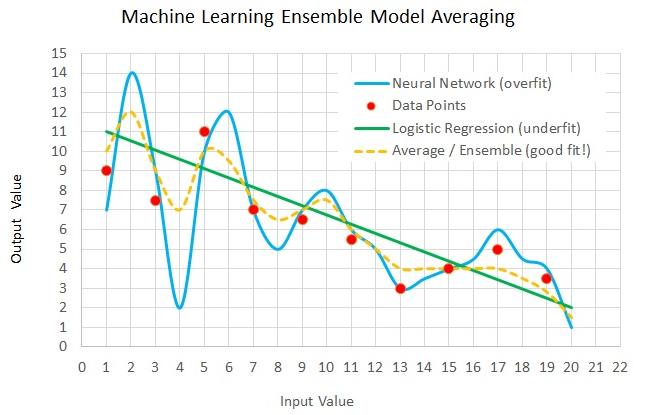
Many other techniques exist such as XGBoost (Extreme Gradient Boosting), an efficient and scalable implementation of gradient boosting widely used in competitions and production. In the Netflix prize, teams found that they obtained the best results by combining their learners with other teams’, and merged into larger and larger teams. The winner and runner-up were both stacked ensembles of over 100 learners, and combining the two ensembles further improved the results.
Thus, model ensembles are a key part of machine learning tookit though they are complex to interpret.
References:
- Pedro Domingos, A Few Useful Things to Know about Machine Learning
- An Introduction to Statistical Learning
- Image source
Comments