Does gradient boosted trees generally perform better than random forest? Let’s see that. But, first what are these methods? Random forest and boosting are ensemble methods, proved to generally perform better than than basic algorithms.
Bagging and Random Forest
Let’s start with bagging (Bootstrap Aggregating), an ensemble of decision trees. Bagging generates m training sets by sampling with replacement from the original data. Each bootstrap sample contains approximately 63.2% unique observations. Predictions are combined by averaging (regression) or majority voting (classification). Bagging is a variance reduction technique.
Random forest is an improvement over bagging. At each split, a random subset of m < p predictors is considered, this is called feature bagging, which decorrelates the trees and makes the forest robust to noise.
Boosting
Random forest builds trees in parallel, while in boosting, trees are built sequentially i.e. each tree is grown using information from previously grown trees. Boosting initializes sample weights uniformly and increases weights for misclassified samples at each step, forcing the next tree to focus on hard cases. It is a bias reduction technique. It can convert weak learners into strong ones, which is why it generally performs better than random forest, though it is more prone to overfitting.
One drawback of gradient boosted trees is that they have a number of hyperparameters to tune, while random forest is practically tuning-free (has only one hyperparameter i.e. number of features to randomly select from set of features). Though both random forests and boosting trees are prone to overfitting, boosting models are more prone.
Random forest build treees in parallel and thus are fast and also efficient. Parallelism can also be achieved in boosted trees. XGBoost1, a gradient boosting library, is quite famous on kaggle2 for its better results. It provides a parallel tree boosting (also known as GBDT, GBM).
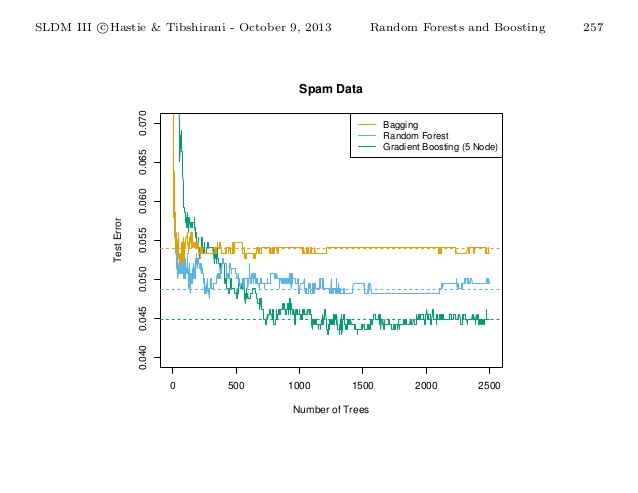
A research paper in 2015 proposes another ensemble method, Randomer forest3, claiming to outperform other methods.
The conclusion is that use gradient boosting with proper parameter tuning. It will almost always beat random forest.
References:
Comments