A loss function is used to optimize the model (e.g. a neural network) you’ve built to solve a problem.
Fundamentals
Loss is defined as the difference between the predicted value by your model and the true value. The most common loss function used in deep neural networks is cross-entropy. It’s defined as:
\[\text{Cross-entropy} = -\sum_{i=1}^n \sum_{j=1}^m y_{i,j}\log(p_{i,j})\]where, \(y_{i,j}\) denotes the true value i.e. 1 if sample i belongs to class j and 0 otherwise.
and \(p_{i,j}\) denotes the probability predicted by your model of sample i belonging to class j.
Accuracy is one of the metrics to measure the performance of your model. Read about other metrics here. It’s defined as:
\[Accuracy = \frac{\text{No of correct predictions}}{\text{Total no of predictions}}\]Most of the time you would observe that the accuracy increases with the decrease in loss. But, it may not be always true as in the given example.
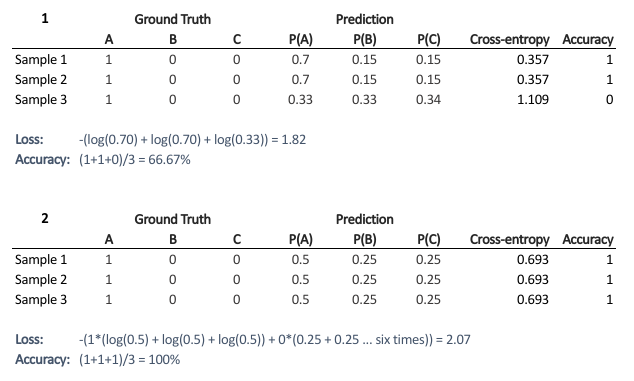
Now, why does this happen? Because accuracy and cross-entropy loss measure fundamentally different things:
-
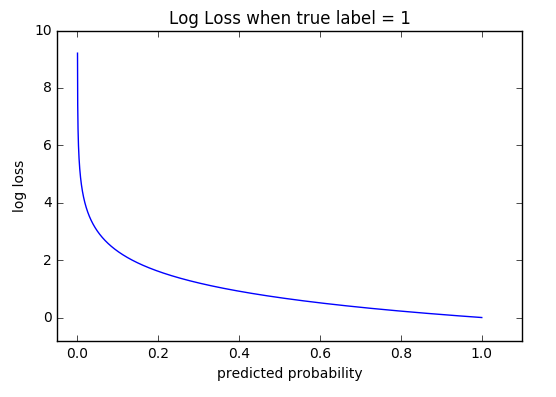
Cross-entropy loss is a continuous measure that penalizes confident wrong predictions the most. A single prediction that is 99% confident but wrong contributes far more to the loss than one that is 51% confident and wrong. It cares about how wrong the model is, not just whether it is wrong.
-
Accuracy is a binary measure, a prediction is either right or wrong, regardless of confidence. A model that predicts 51% confidence correctly gets the same accuracy credit as one that predicts 99% confidence correctly.
This is why they can diverge. A model might be highly accurate but catastrophically wrong on a few examples (high loss, high accuracy). Or it might be well-calibrated but indecisive (low loss, low accuracy). The graph above illustrates this, notice how loss can fluctuate independently of accuracy.
Conclusion
So, which metric should you optimize? The answer depends on what your application demands:
-
Optimize for loss (cross-entropy) when you need well-calibrated probabilities, in medical diagnosis, risk assessment, or any scenario where you rank predictions by confidence. Cross-entropy is a proper scoring rule, meaning it is minimized only when predicted probabilities match the true underlying probabilities. Accuracy can be gamed: a model predicting 51% for every positive class can achieve high accuracy on a balanced dataset, but its probabilities are meaningless.
-
Optimize for accuracy when your application only cares about hard classifications, spam detection, content filtering, or any binary decision where the cost of a wrong prediction is roughly symmetric. If you must make a yes/no choice, accuracy (or better yet, precision/recall) is what ultimately matters.
In practice, monitor both. A widening gap between loss and accuracy is a signal worth investigating, it often indicates mislabeled data, class imbalance, or a model that is memorizing rather than generalizing. Understanding what each metric tells you is the first step toward building models that don’t just perform well on a leaderboard, but actually solve the problem you care about.
References:
Comments