Natural Language Processing deals with the task of making computer understand the human language. The computer understands only 0s and 1s. A language consists of words. So, the first task is to convert word into a combination of 0s and 1s. This is easy. But, a word is nothing without its meaning. Hence, the task we need to solve is to represent the meaning of a word.
Representing words as discrete symbols
One solution to this problem is to use one-hot vector. For example, in the sentence, “I love machine learning”, the word machine can be represented as [0, 0, 1, 0] where 1 corresponds to machine. In the same way, we can represent other words such as learning, [0, 0, 0, 1].
The problem with this approach is that the combination of words has no meaning i.e. to match “machine learning” in a given document. we have got two separate vectors of machine and learning, which unfortunately are orthogonal. Thus, such a search will not yield any result. That is, there is no notion of similarity for one-hot vectors.
Representing words by their contexts
The core idea in this approach is that the words are represented by the context they have i.e. a word’s meaning is given by the words that frequently surrounds it.
word2vec1 is a model for learning word vectors.
While talking about word2vec, we focus on two model variants:
- Skip-grams (SG): Predict context words (position independent) given center word
- Continuous Bag of Words (CBOW): Predict center word from (bag of) context words
Every word in vocabulary is represented by a vector. In Skip-gram model, we use the similarity of word vectors to calculate the probability of a word being context word. The word vectors are adjusted to maximize this probability.
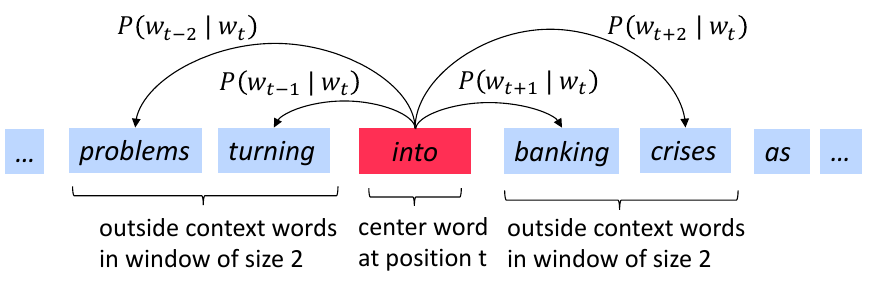
The below figure demonstrates example windows and process for computing \(P(w_{t+2} \mid w_t)\).
We can implement word2vec model in python:
from genism.model import Word2VecWord embeddings
The word vectors, discussed above, are called embeddings (encoding words to numbers) and are learnt in the same way as other hyperparameters in a neural network.
word embeddings are a representation of the semantics of a word, efficiently encoding semantic information that might be relevant to the task at hand.
While designing neural networks, an embedding layer is used. The word2vec model such as CBOW is used to learn word embeddings. Instead of learning the embeddings every time in a network, these pretrained embeddings (already learnt using word2vec) can be used to initialize the embeddings of the network.
This embedding layer is just like a hidden layer, which behaves as a lookup table i.e. instead of doing matrix multiplication, the embedding of a particular word can be extracted from the weight matrix of embeddings using an index. For example “heart” is encoded as 958. Then to get embedding for “heart”, you just take the 958th row of the embedding matrix. It’s possible because the multiplication of a one-hot encoded vector with a matrix returns the row of the matrix corresponding the index of the “on” input unit.
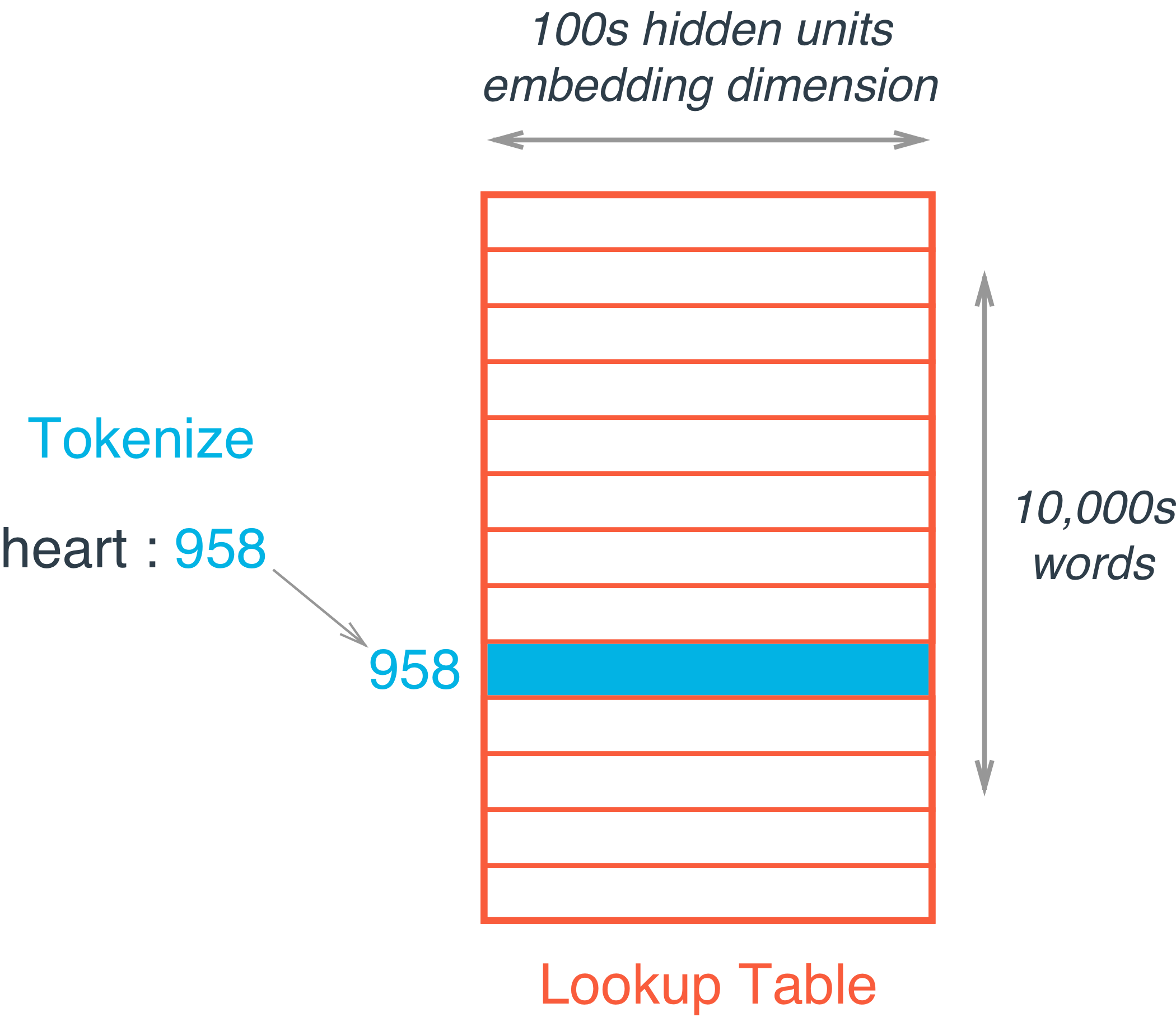
The embeddings are stored as a \(\|V\| \times D\) matrix, where V is our vocabulary, and D is the dimensionality of the embeddings, such that the word assigned index i has its embedding stored in the i‘th row of the matrix. For hidden dimensions (for most of the problems), D, any number between 200-500 should work. It’s kind of a hyperparameter. There’s no precise number.
The embedding vector dimension should be the 4th root of the number of categories i.e. 4th root of the vocab size. You can choose it as a rule of thumb. — Google Developer’s blog2
Beyond word2vec: Contextualized Word Vectors
The two big ideas in the evolution of word representations:
- What is encoded: from individual words to words-in-context (transition from Word2Vec/GloVe to CoVe/ELMo)
- Usage for downstream tasks: from replacing only word embeddings in task-specific models to replacing entire task-specific models (transition from CoVe/ELMo to GPT/BERT)
GloVe/CoVe
GloVe (Global Vectors for Word Representation) learns word vectors by aggregating global word-word co-occurrence statistics from a corpus, rather than just local context windows.
CoVe (Contextualized Word Vectors Learned in Translation) goes a step further. The authors train a Seq2Seq model with attention for Neural Machine Translation and use its encoder (two-layer bi-directional LSTM) to produce context-aware vectors. Since the encoder is bidirectional, each output contains information about both left and right contexts of a token. For downstream tasks, the concatenation of GloVe (token-level) and CoVe (contextualized) vectors is used, they encode different kinds of information, and their combination proves useful.
ELMo
ELMo (Embeddings from Language Models) differs from CoVe by using representations from a language model rather than an NMT model. Just by replacing word embeddings (GloVe) with ELMo embeddings, significant improvements were seen across tasks like question answering and sentiment analysis.
The model consists of a two-layer bi-LSTM language model (forward and backward). Each layer encodes different information: layer 0 captures word-level features, layers 1 and 2 capture words in context. Since different downstream tasks need different kinds of information, ELMo uses task-specific learned scalars to weight and combine representations from all three layers.
Training Options for Embeddings
You have three options for getting embeddings for your model:
- Train from scratch as part of your model, the model will only “know” the classification data, which may not be enough to learn word relationships well.
- Use pretrained embeddings (Word2Vec, GloVe, etc.) and freeze them, the model leverages knowledge from a huge corpus.
- Initialize with pretrained embeddings and fine-tune them with the network, adapts the embeddings to your task-specific data, bringing modest performance gains.
Bag of Words
The Bag of Words model treats each document (text units) as a bag (collection) of words. A set of documents is called a corpus. First, collect all unique words from your corpus to form vocabulary and arrange them into a matrix of vectors by number of occurrences of each word. This matrix is called Document-Term-Matrix where each document is a row and unique words are columns. Each element is called a term frequency, which denotes how many times that term occur in the corresponding document. To calculate the similarity of words, the term-frequency can be compared using cosine-similarity, given by dot product of two vectors and divided by their magnitudes.
References:
1: word2vec: Efficient Estimation of Word Representations in Vector Space ↩
2: Google Developer’s blog ↩
3: An Intuitive Understanding of Word Embeddings: From Count Vectors to Word2Vec
4: CoVe: Learned in Translation: Contextualized Word Vectors
5: ELMo: Deep contextualized word representations
Comments