Data Science
Practical data science concepts from data leakage and feature engineering to statistical thinking, A/B testing, and building end-to-end pipelines.
33 posts
-
 Data Science
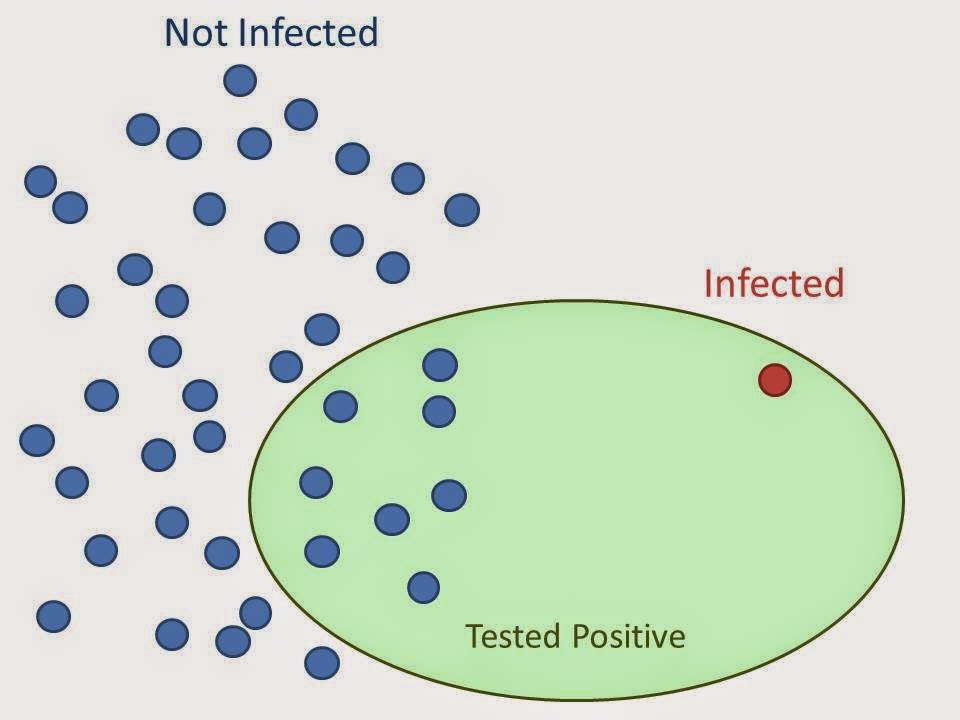
Data ScienceFalse positive paradox
The false positive paradox: why a test with low false positive rate can still produce more false positives than true positives for rare conditions.
-
 Data Science
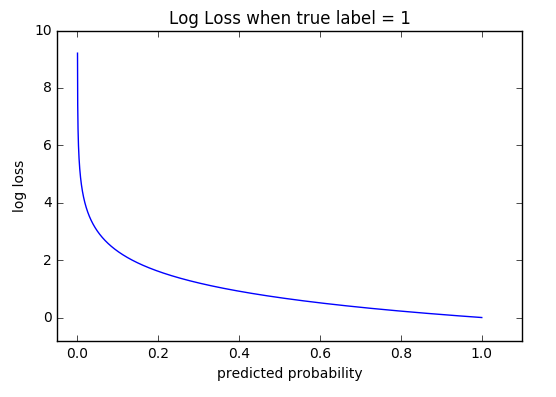
Data ScienceLoss functions
A survey of common loss functions MSE, cross-entropy, hinge loss, with background on entropy, KL divergence, and the MLE connection.
-
 Data Science
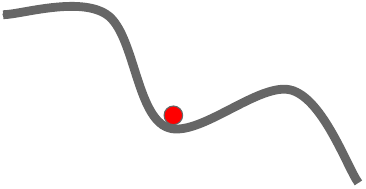
Data ScienceOptimizers
An overview of neural network optimizers: SGD, momentum, RMSProp, and Adam, and how they improve on basic gradient descent.
-
 Data Science
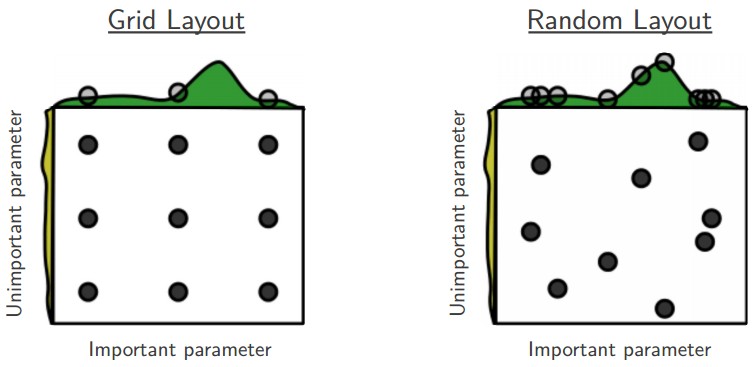
Data ScienceMethods of Hyperparameter optimization
Comparing hyperparameter optimization strategies like grid search, random search, and Bayesian optimization with scikit-learn examples.
-
 Data Science
Data ScienceThe Bayesian Thinking - III
Probabilistic programming with PyMC3, applying Bayesian linear regression using the Bayesian view of statistics.
-
 Data Science
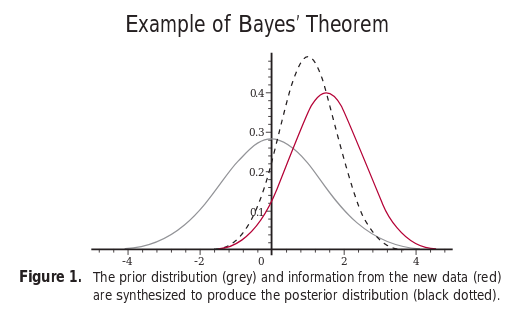
Data ScienceThe Bayesian Thinking - II
Comparing classical, frequentist, and Bayesian probability frameworks, and how Bayesian thinking updates beliefs with new evidence.
-
 Data Science
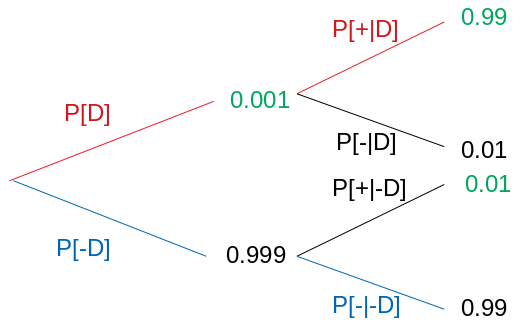
Data ScienceThe Bayesian Thinking - I
An introduction to Bayes' theorem and conditional probability through a disease-testing example that challenges intuitive reasoning.
-
 Data Science
Data ScienceDropout: Prevent overfitting
How dropout regularization prevents overfitting by randomly deactivating neurons during training, effectively ensembling many sub-networks.
-
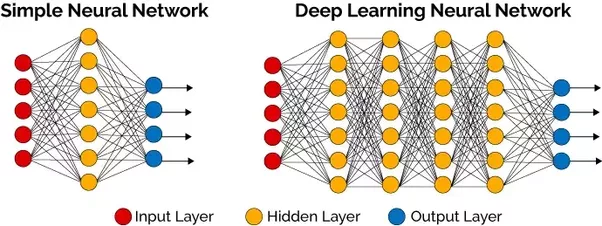 Data Science
Data ScienceHow deep should neural nets be?
Practical guidance on choosing neural network depth and layer sizes, input, hidden, and output layers for different problem types.
-
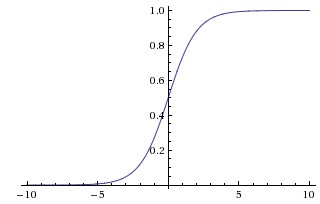 Data Science
Data ScienceDon't use sigmoid: Neural Nets
Why sigmoid activation functions should be avoided in deep neural networks, and what alternatives like ReLU offer instead.
-
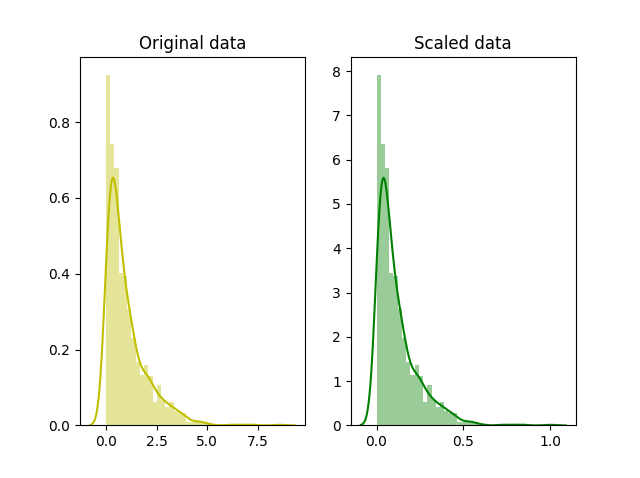 Data Science
Data ScienceScaling vs Normalization
The difference between feature scaling (min-max) and normalization (standardization), and when to apply each in machine learning pipelines.
-
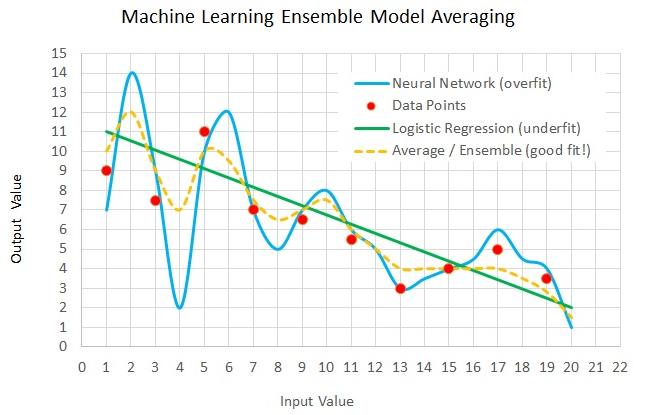 Data Science
Data ScienceEnsembling is the key
An overview of ensemble learning methods: bagging, random forest, boosting, and stacking, and why combining models often outperforms any single algorithm.
-
Data Science
Computational graphs: Backpropagation
Backpropagation explained via computational graphs, a local, chain-rule-based method for computing gradients efficiently in neural networks.
-
 Data Science
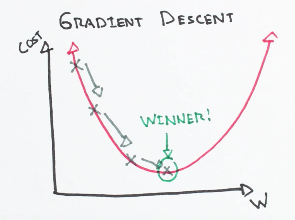
Data ScienceGradient descent: The core of neural networks
How gradient descent works to optimize neural network weights by following the steepest direction of the loss function.
-
 Data Science
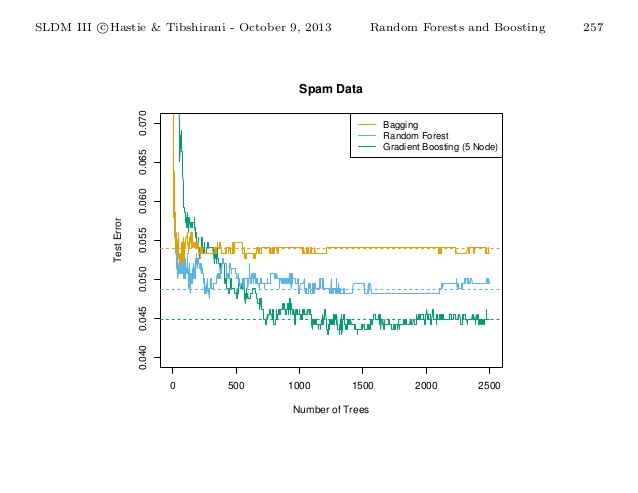
Data ScienceGradient boosted trees: Better than random forest?
Comparing gradient boosted trees and random forests, their differences in training strategy, tuning requirements, and when to prefer each.
-
 Data Science
Data ScienceLinear algebra: The essence behind deep learning
How linear algebra underpins deep learning from score functions and weight matrices to image classification with neural networks.
-
 Data Science
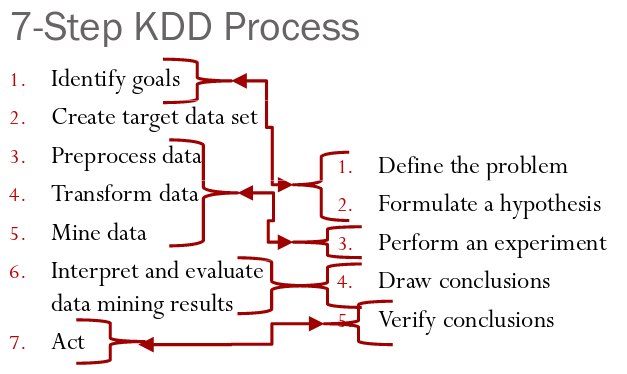
Data ScienceData Mining: Knowledge discovery in databases
An overview of the KDD (Knowledge Discovery in Databases) process and how data mining, machine learning, and data science relate to each other.
-
 Data Science
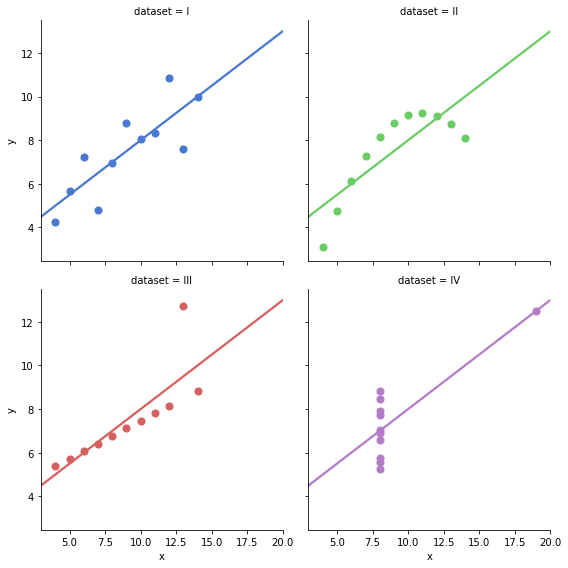
Data ScienceAnscombe's Quartet
Anscombe's quartet illustrates why visualizing data matters, four datasets with nearly identical statistics but completely different distributions.
-
Data Science
The Curse of Dimensionality
Why increasing the number of features degrades kNN performance, the curse of dimensionality explained intuitively and mathematically.
-
Data Science
Dealing with categorical data
Techniques for encoding categorical variables in machine learning models, including dummy variables and one-hot encoding.
-
Data Science
Regularization
How regularization techniques, L1 (Lasso) and L2 (Ridge), add penalty terms to the loss function to combat overfitting in linear models.
-
 Data Science
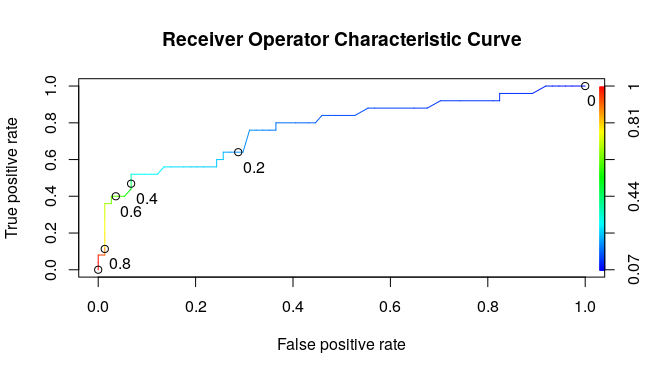
Data ScienceEvaluation metrics for classification and False positives
Guide to classification evaluation metrics: confusion matrix, precision, recall, specificity, F1, balanced accuracy, ROC-AUC, PR curves, handling imbalanced datasets, and when to choose each metric.
-
 Data Science
Data ScienceSimplicity doesn't imply accuracy
Examining Occam's razor in machine learning, why simpler models aren't always more accurate and how complexity relates to overfitting.
-
 Data Science
Data Sciencep-Value
Understanding p-values and statistical significance in the context of simple linear regression and hypothesis testing.
-
 Data Science
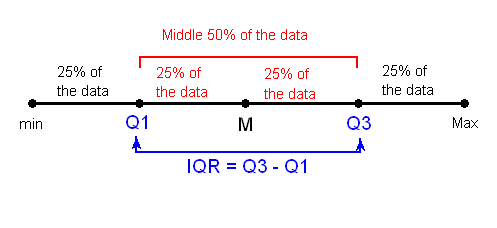
Data ScienceOut-liars
How to detect and handle outliers in data using the Interquartile Range (IQR) method and box plots.
-
 Data Science
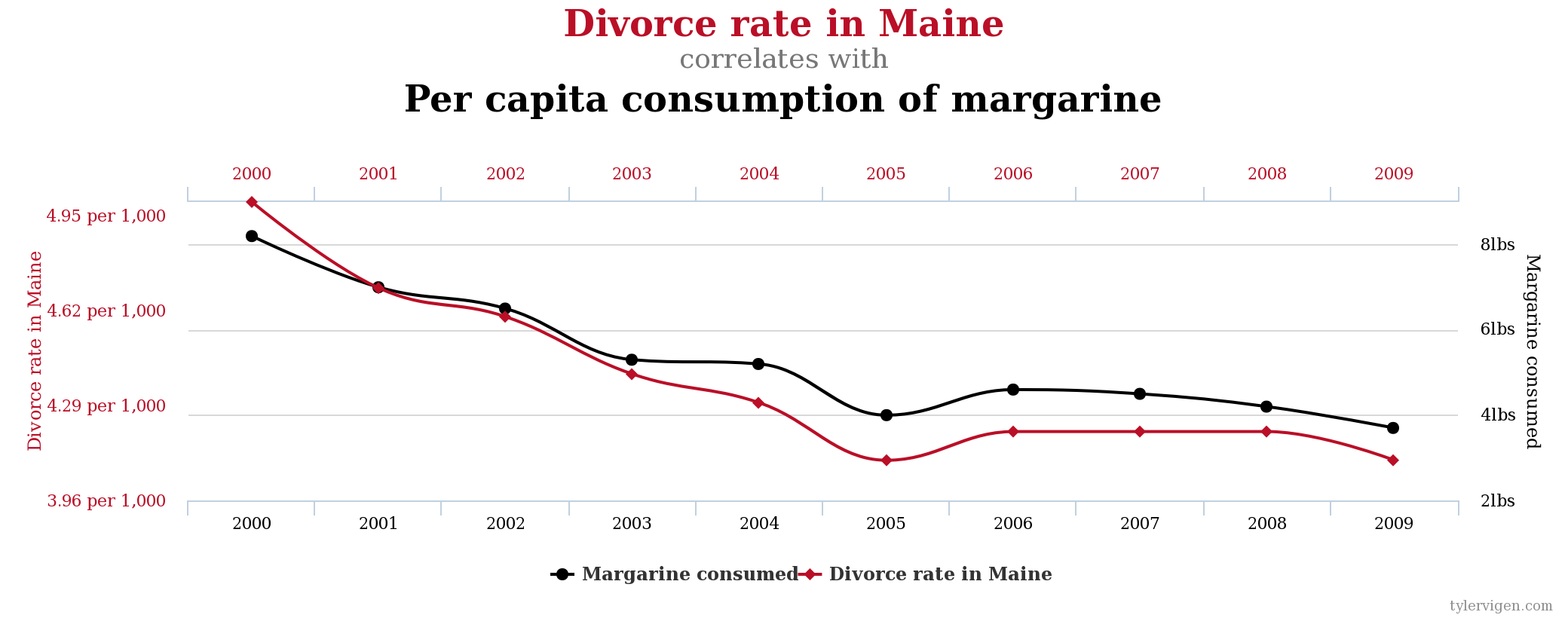
Data ScienceCorrelation is not causation
Why correlation between two variables does not imply causation, illustrated with classic examples of spurious correlations.
-
 Data Science
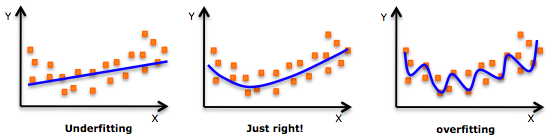
Data ScienceOverfitting and Underfitting
Explaining overfitting and underfitting in machine learning, and how the bias-variance tradeoff helps build better-generalizing models.
-
 Data Science
Data ScienceData leakage: A big problem
Understanding data leakage when training data inadvertently contains information about the target, causing unrealistically good but unreliable model performance.
-
 Data Science
Data ScienceSimpson's paradox
Simpson's paradox explained through UC Berkeley's 1973 admissions data, a trend that reverses when data is aggregated across groups.
-
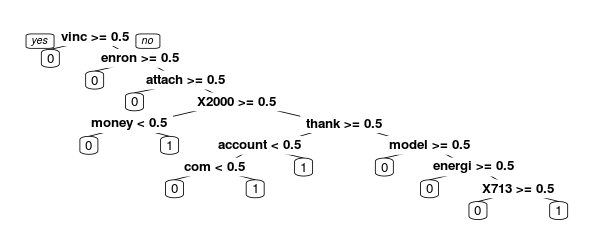 Data Science
Data ScienceEmail spam filtering: Text analysis in R
Building and evaluating an email spam filter using text analytics and machine learning in R.
-
 Data Science
Data ScienceFriendship paradox: facebook
Exploring the friendship paradox, phenomenon where most people have fewer friends than their friends have on average, using Facebook data and Python.
-
 Data Science
Data ScienceMoneyball: Why no prediction can't be made for baseball champion
Using logistic regression in R to explore why ML cannot reliably predict the baseball World Series champion.
-
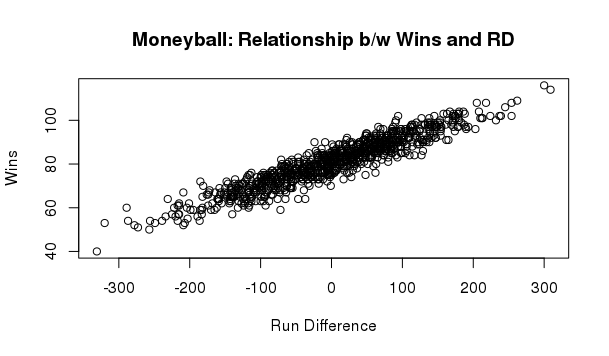 Data Science
Data ScienceMoneyball: How linear regression changed baseball
How Oakland A's used linear regression in R to identify undervalued players and compete despite limited budget.