Knowledge discovery in databases (KDD) is a 7 step process to search for hidden knowledge in data. Data Mining refers to the analysis step in the KDD process.
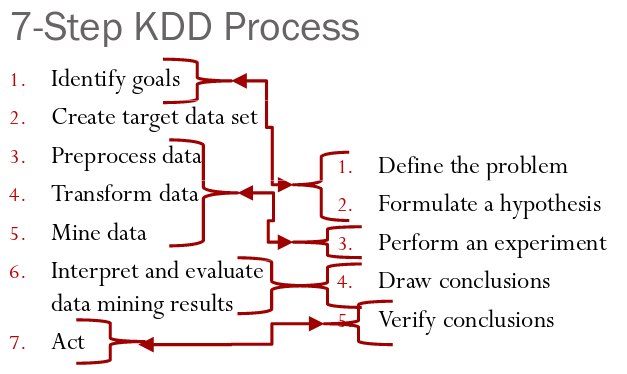
The KDD Process
When we’re working on a data science project, we’re performing some kind of KDD process with the objective of solving a problem. Data science is, infact, multidisciplinary. Everything from data mining to visualizing results is data science.
A critical step in the KDD process is Transformation, where data is converted into a suitable form for analysis. Dimensionality reduction techniques are often applied here to handle high-dimensional data. Methods like PCA (Principal Component Analysis), LDA (Linear Discriminant Analysis), and t-SNE (t-distributed Stochastic Neighbor Embedding) reduce the number of features while retaining important structure. PCA preserves variance using orthogonal principal components derived from eigendecomposition or SVD. LDA maximizes separation between classes. t-SNE is a non-linear method that preserves local structure for visualization. These techniques help overcome the curse of dimensionality, where data becomes sparse and distances lose meaning as the number of features grows.
Machine learning, on the other hand, is a technique broadly used in data mining (thus in data science) to build models based on data so that it can predict the future outcomes.
The term data science is relatively new compared to others. Normally, the terms data mining and KDD are used synonymously.
References:
Knowledge Discovery in Databases
Comments