Email spam1, also known as junk email, is a type of electronic spam where unsolicited messages are sent by email.
As a result of the huge number of spam emails being sent across the Internet each day, most email providers offer a spam filter that automatically flags likely spam messages and separates them from the ham. Although these filters use a number of techniques, most rely heavily on the analysis of the contents of an email via text analytics.
Let’s build and evaluate a spam filter using a publicly available dataset emails.csv2 with the codebook.
# load the dataset
> emails = read.csv('emails.csv', stringsAsFactors = FALSE)
> str(emails)
'data.frame': 5728 obs. of 2 variables:
$ text: chr "Subject: naturally irresistible your corporate identity lt is really hard to recollect a company : the market is full of suqg"| __truncated__ "Subject: the stock trading gunslinger fanny is merrill but muzo not colza attainder and penultimate like esmark perspicuous ra"| __truncated__ "Subject: unbelievable new homes made easy im wanting to show you this homeowner you have been pre - approved for a $ 454 , 1"| __truncated__ "Subject: 4 color printing special request additional information now ! click here click here for a printable version of our o"| __truncated__ ...
$ spam: int 1 1 1 1 1 1 1 1 1 1 ...
# confusion matrix of emails whether spam or not
> table(emails$spam)
0 1
4360 1368 Follow the standard steps to build and pre-process the corpus:
# load text mining package
> library(tm)
# Build a new corpus variable called corpus
> corpus = VCorpus(VectorSource(emails$text))
# convert the text to lowercase
> corpus = tm_map(corpus, content_transformer(tolower))
> corpus = tm_map(corpus, PlainTextDocument)
# remove all punctuation from the corpus
> corpus = tm_map(corpus, removePunctuation)
# remove all English stopwords from the corpus
> corpus = tm_map(corpus, removeWords, stopwords("en"))
# stem the words in the corpus
> corpus = tm_map(corpus, stemDocument)We are now ready to extract the word frequencies to be used in our prediction problem.
Let’s create a DocumentTermMatrix where the rows correspond to documents (emails), and the columns correspond to words.
# Build a document term matrix from the corpus
> dtm = DocumentTermMatrix(corpus)
> dtm
<<DocumentTermMatrix (documents: 5728, terms: 28687)>>
Non-/sparse entries: 481719/163837417
Sparsity : 100%
Maximal term length: 24
Weighting : term frequency (tf)To obtain a more reasonable number of terms, limit dtm to contain terms appearing in at least 5% of documents.
# Remove sparse terms (that don't appear very often)
> spdtm = removeSparseTerms(dtm, 0.95)
> spdtm
<<DocumentTermMatrix (documents: 5728, terms: 330)>>
Non-/sparse entries: 213551/1676689
Sparsity : 89%
Maximal term length: 10
Weighting : term frequency (tf)# Convert spdtm to a data frame
> emailsSparse = as.data.frame(as.matrix(spdtm))
# make variable names of emailsSparse valid i.e. R-friendly (to convert variables names starting with numbers)
> colnames(emailsSparse) = make.names(colnames(emailsSparse))# word stem that shows up most frequently across all the emails:
> sort(colSums(emailsSparse))
vkamin begin either done sorri lot
301 317 318 337 343 348
mention thought bring idea better immedi
355 367 374 378 383 385
without mean write happi repli life
389 390 390 396 397 400
experi involv specif arrang creat read
405 405 407 410 413 413
wish open realli link say respond
414 416 417 421 423 430
sever keep etc anoth run info
430 431 434 435 437 438
togeth short sincer buy due alreadi
438 439 441 442 445 446
line allow recent special given believ
448 450 451 451 453 456
design put remov X853 wednesday type
457 458 460 462 464 466
public full hear join effect effort
468 469 469 469 471 473
tuesday robert locat check area final
474 482 485 488 489 490
increas soon analysi sure deal return
491 492 495 495 498 509
place onlin success sinc understand still
516 518 519 521 521 523
import comment confirm hello long thing
530 531 532 534 534 535
point appreci feel howev member hour
536 541 543 545 545 548
net continu event expect suggest unit
548 552 552 554 554 554
resourc case version corpor applic engin
556 561 564 565 567 571
part attend thursday might morn abl
571 573 575 577 586 590
assist differ intern updat move mark
598 598 606 606 612 613
depart even made internet high cours
621 622 622 623 624 626
contract gibner end right per invit
629 633 635 639 642 647
approv real monday result school kevin
648 648 649 655 655 656
direct home detail tri form problem
657 660 661 661 664 666
web doc deriv don april note
668 675 676 676 682 688
relat websit juli director complet rate
694 700 701 705 707 717
valu futur student set within requir
721 722 726 727 732 736
softwar book mani person click file
739 756 758 767 769 770
addit money associ particip term access
774 776 777 782 786 789
custom possibl copi oper cost respons
796 796 797 820 821 824
today account base great dear london
828 829 837 837 838 843
friday support secur hope much back
854 854 857 858 861 864
way find invest ask start shall
864 867 867 871 880 884
origin come plan financi two site
892 903 904 909 911 913
opportun team first resum issu data
918 926 929 933 944 955
month peopl credit industri process review
958 958 960 970 975 976
talk last phone X000 chang fax
981 998 1001 1007 1035 1038
john current stinson give univers offic
1042 1044 1051 1055 1059 1068
gas schedul financ state name X713
1070 1071 1073 1086 1089 1097
good posit crenshaw system well sent
1097 1104 1115 1118 1125 1126
visit free next. avail question address
1126 1141 1145 1152 1152 1154
offer attach number date product order
1171 1176 1182 1187 1197 1210
think includ report best confer now
1216 1238 1279 1291 1297 1300
www discuss interview servic communic request
1323 1326 1333 1337 1343 1344
just take trade send provid list
1354 1361 1366 1379 1405 1410
help program option want project contact
1430 1438 1488 1488 1522 1543
present follow receiv see houston http
1543 1552 1557 1567 1582 1609
edu call shirley corp week interest
1627 1687 1689 1692 1758 1814
day also develop make year let
1860 1864 1882 1884 1890 1963
messag look regard email one power
1983 2003 2045 2066 2108 2117
energi model risk mail new compani
2179 2199 2267 2269 2281 2290
busi need use like get may
2313 2328 2330 2352 2462 2465
manag group know meet price inform
2600 2604 2614 2623 2694 2701
work market research X2001 time forward
2708 2750 2820 3089 3145 3161
thank can kaminski X2000 pleas com
3730 4257 4801 4967 5113 5443
hou will vinc subject ect enron
5577 8252 8532 10202 11427 13388
# Add dependent variable to this dataset
> emailsSparse$spam = emails$spam
# most frequent words in ham:
> sort(colSums(subset(emailsSparse, spam == 0)))
spam life remov money onlin without
0 80 103 114 173 191
websit click special wish repli buy
194 217 226 229 239 243
net link immedi done mean design
243 247 249 254 259 261
lot effect info either read write
268 270 273 279 279 286
line begin sorri success involv creat
289 291 293 293 294 299
softwar better vkamin say keep bring
299 301 301 305 306 311
believ full increas realli mention thought
313 317 320 324 325 325
idea invest secur specif sever experi
327 327 337 338 340 346
thing allow check due type happi
347 348 351 351 352 354
return expect short effort open internet
355 356 357 358 360 361
sincer public recent anoth alreadi home
361 364 368 369 372 375
made respond given etc put within
380 382 383 385 385 386
place right version hello sure area
388 390 390 395 396 397
run arrang account join hour locat
398 399 401 403 404 406
togeth engin import per corpor high
406 411 411 412 414 416
result hear final deal applic even
418 420 422 423 428 429
web custom soon long sinc futur
430 433 435 436 439 440
member X000 event don part feel
446 447 447 450 450 453
tuesday wednesday still unit site X853
454 456 457 457 458 461
continu understand resourc robert analysi form
464 464 466 466 468 468
point assist confirm differ intern might
474 475 485 489 489 490
real case howev comment abl complet
490 492 496 505 515 515
rate appreci tri move updat approv
516 518 521 526 527 533
suggest free contract detail morn end
533 535 544 546 546 550
mani attend thursday direct requir cours
550 558 558 561 562 567
person relat depart today start way
569 573 575 577 580 586
mark valu problem peopl note school
588 590 593 599 600 607
invit access term juli monday gibner
614 617 625 630 630 633
base director offer cost addit kevin
635 640 643 646 648 654
great set file find much oper
655 658 659 665 669 669
order deriv doc april book address
669 673 673 677 680 693
copi financi month student respons possibl
700 702 709 710 711 712
associ particip now first industri dear
715 717 725 726 731 734
support plan back name come opportun
734 738 739 745 748 760
report product two origin ask credit
772 776 787 796 797 798
state system process hope london just
806 816 826 828 828 830
receiv chang review current shall friday
830 831 834 841 844 847
team phone issu data avail last
850 858 865 868 872 874
good give www gas list posit
876 883 897 905 907 917
visit includ resum best offic servic
920 924 928 933 935 942
talk number well fax provid sent
943 951 961 963 970 971
next. send http john univers financ
975 986 1009 1022 1025 1038
stinson schedul take date want question
1051 1054 1057 1060 1068 1069
program think X713 crenshaw attach trade
1080 1084 1097 1115 1155 1167
help email compani request see communic
1168 1201 1225 1227 1238 1251
confer discuss make contact follow interview
1264 1270 1281 1301 1308 1320
project mail present busi interest option
1328 1352 1397 1416 1429 1432
day call one year week messag
1440 1497 1516 1523 1527 1538
houston also look edu corp shirley
1577 1604 1607 1620 1643 1687
develop get new use let regard
1691 1768 1777 1784 1856 1859
inform need power may like risk
1883 1890 1972 1976 1980 2097
energi market model price work manag
2124 2150 2170 2191 2293 2334
know group meet time research forward
2345 2474 2544 2552 2752 2952
X2001 can thank com pleas kaminski
3060 3426 3558 4444 4494 4801
X2000 hou will vinc subject ect
4935 5569 6802 8531 8625 11417
enron
13388
# most frequent words in spam:
> sort(colSums(subset(emailsSparse, spam == 1)))
X713 crenshaw enron gibner kaminski stinson
0 0 0 0 0 0
vkamin X853 vinc doc kevin shirley
0 1 1 2 2 2
deriv april houston resum edu friday
3 5 5 5 7 7
hou wednesday ect arrang interview attend
8 8 10 11 13 15
london robert student schedul thursday monday
15 16 16 17 17 19
john tuesday attach suggest appreci mark
20 20 21 21 23 25
begin comment analysi X2001 model hope
26 26 27 29 29 30
mention X2000 togeth confer invit univers
30 32 32 33 33 34
financ talk either run morn shall
35 38 39 39 40 40
happi thought depart confirm respond school
42 42 46 47 48 48
corp etc hear howev sorri idea
49 49 49 49 50 51
energi discuss open option soon understand
55 56 56 56 57 57
cours experi associ point bring director
59 59 62 62 63 65
particip anoth join still final research
65 66 66 66 68 68
case set specif given juli problem
69 69 69 70 71 73
put alreadi ask abl deal fax
73 74 74 75 75 75
book team issu locat meet updat
76 76 79 79 79 79
lot sincer better short sinc done
80 80 82 82 82 83
question recent possibl contract end move
83 83 84 85 85 86
data might continu note feel resourc
87 87 88 88 90 90
sever area communic realli due direct
90 92 92 93 94 96
origin copi unit long member sure
96 97 97 98 99 99
allow dear public write event let
102 104 104 104 105 107
differ file involv respons creat type
109 111 111 113 114 114
approv detail effort intern request say
115 115 115 117 117 118
import support part relat assist last
119 120 121 121 123 124
two back keep addit date place
124 125 125 126 127 128
group mean valu think offic read
130 131 131 132 133 134
immedi check applic hello tri review
136 137 139 139 140 142
believ phone hour power present process
143 143 144 145 146 149
corpor oper full return come sent
151 151 152 154 155 155
opportun real repli line engin term
158 158 158 159 160 161
credit well gas info plan next.
162 164 165 165 166 170
risk increas access give thank link
170 171 172 172 172 174
requir version cost great wish regard
174 174 175 182 185 186
posit thing call develop complet much
187 188 190 191 192 192
even project design form expect person
193 194 196 196 198 198
without buy trade effect rate base
198 199 199 201 201 202
find current first chang visit financi
202 203 203 204 206 207
high mani forward good special don
208 208 209 221 225 226
success per number week result web
226 230 231 231 237 238
industri contact made follow month right
239 242 242 244 249 249
today also help internet manag know
251 260 262 262 266 269
way avail state futur home start
278 280 280 282 285 300
system take net includ life see
302 304 305 314 320 329
name onlin within remov best program
344 345 346 357 358 358
peopl custom year like interest send
359 363 367 372 385 393
servic look work day want product
395 396 415 420 420 421
www account provid need softwar messag
426 428 435 438 440 445
site address may list price new
455 461 489 503 503 504
websit report secur just offer invest
506 507 520 524 528 540
order use click X000 now one
541 546 552 560 575 592
time http market make free pleas
593 600 600 603 606 619
money get receiv inform can email
662 694 727 818 831 865
busi mail com compani spam will
897 917 999 1065 1368 1450
subject
1577 The lists of most common words are significantly different between the spam and ham emails.
A word stem like enron, which is extremely common in the ham emails but does not occur in any spam message, will help us correctly identify a large number of ham messages.
Now, let’s build our machine learning models.
# convert the dependent variable to a factor
> emailsSparse$spam = as.factor(emailsSparse$spam)
# split the dataset into training and testing set
> library(caTools)
> set.seed(123)
> spl = sample.split(emailsSparse$spam, 0.7)
> train = subset(emailsSparse, spl == TRUE)
> test = subset(emailsSparse, spl == FALSE)Logistic Regresssion model
# Build a logistic regression model
> spamLog = glm(spam~., data=train, family="binomial")
Warning messages:
1: glm.fit: algorithm did not converge
2: glm.fit: fitted probabilities numerically 0 or 1 occurred
> summary(spamLog)
Call:
glm(formula = spam ~ ., family = "binomial", data = train)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.011 0.000 0.000 0.000 1.354
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.082e+01 1.055e+04 -0.003 0.998
X000 1.474e+01 1.058e+04 0.001 0.999
X2000 -3.631e+01 1.556e+04 -0.002 0.998
X2001 -3.215e+01 1.318e+04 -0.002 0.998
X713 -2.427e+01 2.914e+04 -0.001 0.999
X853 -1.212e+00 5.942e+04 0.000 1.000
abl -2.049e+00 2.088e+04 0.000 1.000
access -1.480e+01 1.335e+04 -0.001 0.999
account 2.488e+01 8.165e+03 0.003 0.998
addit 1.463e+00 2.703e+04 0.000 1.000
address -4.613e+00 1.113e+04 0.000 1.000
allow 1.899e+01 6.436e+03 0.003 0.998
alreadi -2.407e+01 3.319e+04 -0.001 0.999
also 2.990e+01 1.378e+04 0.002 0.998
analysi -2.405e+01 3.860e+04 -0.001 1.000
anoth -8.744e+00 2.032e+04 0.000 1.000
applic -2.649e+00 1.674e+04 0.000 1.000
appreci -2.145e+01 2.762e+04 -0.001 0.999
approv -1.302e+00 1.589e+04 0.000 1.000
april -2.620e+01 2.208e+04 -0.001 0.999
area 2.041e+01 2.266e+04 0.001 0.999
arrang 1.069e+01 2.135e+04 0.001 1.000
ask -7.746e+00 1.976e+04 0.000 1.000
assist -1.128e+01 2.490e+04 0.000 1.000
associ 9.049e+00 1.909e+04 0.000 1.000
attach -1.037e+01 1.534e+04 -0.001 0.999
attend -3.451e+01 3.257e+04 -0.001 0.999
avail 8.651e+00 1.709e+04 0.001 1.000
back -1.323e+01 2.272e+04 -0.001 1.000
base -1.354e+01 2.122e+04 -0.001 0.999
begin 2.228e+01 2.973e+04 0.001 0.999
believ 3.233e+01 2.136e+04 0.002 0.999
best -8.201e+00 1.333e+03 -0.006 0.995
better 4.263e+01 2.360e+04 0.002 0.999
book 4.301e+00 2.024e+04 0.000 1.000
bring 1.607e+01 6.767e+04 0.000 1.000
busi -4.803e+00 1.000e+04 0.000 1.000
buy 4.170e+01 3.892e+04 0.001 0.999
call -1.145e+00 1.111e+04 0.000 1.000
can 3.762e+00 7.674e+03 0.000 1.000
case -3.372e+01 2.880e+04 -0.001 0.999
chang -2.717e+01 2.215e+04 -0.001 0.999
check 1.425e+00 1.963e+04 0.000 1.000
click 1.376e+01 7.077e+03 0.002 0.998
com 1.936e+00 4.039e+03 0.000 1.000
come -1.166e+00 1.511e+04 0.000 1.000
comment -3.251e+00 3.387e+04 0.000 1.000
communic 1.580e+01 8.958e+03 0.002 0.999
compani 4.781e+00 9.186e+03 0.001 1.000
complet -1.363e+01 2.024e+04 -0.001 0.999
confer -7.503e-01 8.557e+03 0.000 1.000
confirm -1.300e+01 1.514e+04 -0.001 0.999
contact 1.530e+00 1.262e+04 0.000 1.000
continu 1.487e+01 1.535e+04 0.001 0.999
contract -1.295e+01 1.498e+04 -0.001 0.999
copi -4.274e+01 3.070e+04 -0.001 0.999
corp 1.606e+01 2.708e+04 0.001 1.000
corpor -8.286e-01 2.818e+04 0.000 1.000
cost -1.938e+00 1.833e+04 0.000 1.000
cours 1.665e+01 1.834e+04 0.001 0.999
creat 1.338e+01 3.946e+04 0.000 1.000
credit 2.617e+01 1.314e+04 0.002 0.998
crenshaw 9.994e+01 6.769e+04 0.001 0.999
current 3.629e+00 1.707e+04 0.000 1.000
custom 1.829e+01 1.008e+04 0.002 0.999
data -2.609e+01 2.271e+04 -0.001 0.999
date -2.786e+00 1.699e+04 0.000 1.000
day -6.100e+00 5.866e+03 -0.001 0.999
deal -1.129e+01 1.448e+04 -0.001 0.999
dear -2.313e+00 2.306e+04 0.000 1.000
depart -4.068e+01 2.509e+04 -0.002 0.999
deriv -4.971e+01 3.587e+04 -0.001 0.999
design -7.923e+00 2.939e+04 0.000 1.000
detail 1.197e+01 2.301e+04 0.001 1.000
develop 5.976e+00 9.455e+03 0.001 0.999
differ -2.293e+00 1.075e+04 0.000 1.000
direct -2.051e+01 3.194e+04 -0.001 0.999
director -1.770e+01 1.793e+04 -0.001 0.999
discuss -1.051e+01 1.915e+04 -0.001 1.000
doc -2.597e+01 2.603e+04 -0.001 0.999
don 2.129e+01 1.456e+04 0.001 0.999
done 6.828e+00 1.882e+04 0.000 1.000
due -4.163e+00 3.532e+04 0.000 1.000
ect 8.685e-01 5.342e+03 0.000 1.000
edu -2.122e-01 6.917e+02 0.000 1.000
effect 1.948e+01 2.100e+04 0.001 0.999
effort 1.606e+01 5.670e+04 0.000 1.000
either -2.744e+01 4.000e+04 -0.001 0.999
email 3.833e+00 1.186e+04 0.000 1.000
end -1.311e+01 2.938e+04 0.000 1.000
energi -1.620e+01 1.646e+04 -0.001 0.999
engin 2.664e+01 2.394e+04 0.001 0.999
enron -8.789e+00 5.719e+03 -0.002 0.999
etc 9.470e-01 1.569e+04 0.000 1.000
even -1.654e+01 2.289e+04 -0.001 0.999
event 1.694e+01 1.851e+04 0.001 0.999
expect -1.179e+01 1.914e+04 -0.001 1.000
experi 2.460e+00 2.240e+04 0.000 1.000
fax 3.537e+00 3.386e+04 0.000 1.000
feel 2.596e+00 2.348e+04 0.000 1.000
file -2.943e+01 2.165e+04 -0.001 0.999
final 8.075e+00 5.008e+04 0.000 1.000
financ -9.122e+00 7.524e+03 -0.001 0.999
financi -9.747e+00 1.727e+04 -0.001 1.000
find -2.623e+00 9.727e+03 0.000 1.000
first -4.666e-01 2.043e+04 0.000 1.000
follow 1.766e+01 3.080e+03 0.006 0.995
form 8.483e+00 1.674e+04 0.001 1.000
forward -3.484e+00 1.864e+04 0.000 1.000
free 6.113e+00 8.121e+03 0.001 0.999
friday -1.146e+01 1.996e+04 -0.001 1.000
full 2.125e+01 2.190e+04 0.001 0.999
futur 4.146e+01 1.439e+04 0.003 0.998
gas -3.901e+00 4.160e+03 -0.001 0.999
get 5.154e+00 9.737e+03 0.001 1.000
gibner 2.901e+01 2.460e+04 0.001 0.999
give -2.518e+01 2.130e+04 -0.001 0.999
given -2.186e+01 5.426e+04 0.000 1.000
good 5.399e+00 1.619e+04 0.000 1.000
great 1.222e+01 1.090e+04 0.001 0.999
group 5.264e-01 1.037e+04 0.000 1.000
happi 1.939e-02 1.202e+04 0.000 1.000
hear 2.887e+01 2.281e+04 0.001 0.999
hello 2.166e+01 1.361e+04 0.002 0.999
help 1.731e+01 2.791e+03 0.006 0.995
high -1.982e+00 2.554e+04 0.000 1.000
home 5.973e+00 8.965e+03 0.001 0.999
hope -1.435e+01 2.179e+04 -0.001 0.999
hou 6.852e+00 6.437e+03 0.001 0.999
hour 2.478e+00 1.333e+04 0.000 1.000
houston -1.855e+01 7.305e+03 -0.003 0.998
howev -3.449e+01 3.562e+04 -0.001 0.999
http 2.528e+01 2.107e+04 0.001 0.999
idea -1.845e+01 3.892e+04 0.000 1.000
immedi 6.285e+01 3.346e+04 0.002 0.999
import -1.859e+00 2.236e+04 0.000 1.000
includ -3.454e+00 1.799e+04 0.000 1.000
increas 6.476e+00 2.329e+04 0.000 1.000
industri -3.160e+01 2.373e+04 -0.001 0.999
info -1.255e+00 4.857e+03 0.000 1.000
inform 2.078e+01 8.549e+03 0.002 0.998
interest 2.698e+01 1.159e+04 0.002 0.998
intern -7.991e+00 3.351e+04 0.000 1.000
internet 8.749e+00 1.100e+04 0.001 0.999
interview -1.640e+01 1.873e+04 -0.001 0.999
invest 3.201e+01 2.393e+04 0.001 0.999
invit 4.304e+00 2.215e+04 0.000 1.000
involv 3.815e+01 3.315e+04 0.001 0.999
issu -3.708e+01 3.396e+04 -0.001 0.999
john -5.326e-01 2.856e+04 0.000 1.000
join -3.824e+01 2.334e+04 -0.002 0.999
juli -1.358e+01 3.009e+04 0.000 1.000
just -1.021e+01 1.114e+04 -0.001 0.999
kaminski -1.812e+01 6.029e+03 -0.003 0.998
keep 1.867e+01 2.782e+04 0.001 0.999
kevin -3.779e+01 4.738e+04 -0.001 0.999
know 1.277e+01 1.526e+04 0.001 0.999
last 1.046e+00 1.372e+04 0.000 1.000
let -2.763e+01 1.462e+04 -0.002 0.998
life 5.812e+01 3.864e+04 0.002 0.999
like 5.649e+00 7.660e+03 0.001 0.999
line 8.743e+00 1.236e+04 0.001 0.999
link -6.929e+00 1.345e+04 -0.001 1.000
list -8.692e+00 2.149e+03 -0.004 0.997
locat 2.073e+01 1.597e+04 0.001 0.999
london 6.745e+00 1.642e+04 0.000 1.000
long -1.489e+01 1.934e+04 -0.001 0.999
look -7.031e+00 1.563e+04 0.000 1.000
lot -1.964e+01 1.321e+04 -0.001 0.999
made 2.820e+00 2.743e+04 0.000 1.000
mail 7.584e+00 1.021e+04 0.001 0.999
make 2.901e+01 1.528e+04 0.002 0.998
manag 6.014e+00 1.445e+04 0.000 1.000
mani 1.885e+01 1.442e+04 0.001 0.999
mark -3.350e+01 3.208e+04 -0.001 0.999
market 7.895e+00 8.012e+03 0.001 0.999
may -9.434e+00 1.397e+04 -0.001 0.999
mean 6.078e-01 2.952e+04 0.000 1.000
meet -1.063e+00 1.263e+04 0.000 1.000
member 1.381e+01 2.343e+04 0.001 1.000
mention -2.279e+01 2.714e+04 -0.001 0.999
messag 1.716e+01 2.562e+03 0.007 0.995
might 1.244e+01 1.753e+04 0.001 0.999
model -2.292e+01 1.049e+04 -0.002 0.998
monday -1.034e+00 3.233e+04 0.000 1.000
money 3.264e+01 1.321e+04 0.002 0.998
month -3.727e+00 1.112e+04 0.000 1.000
morn -2.645e+01 3.403e+04 -0.001 0.999
move -3.834e+01 3.011e+04 -0.001 0.999
much 3.775e-01 1.392e+04 0.000 1.000
name 1.672e+01 1.322e+04 0.001 0.999
need 8.437e-01 1.221e+04 0.000 1.000
net 1.256e+01 2.197e+04 0.001 1.000
new 1.003e+00 1.009e+04 0.000 1.000
next. 1.492e+01 1.724e+04 0.001 0.999
note 1.446e+01 2.294e+04 0.001 0.999
now 3.790e+01 1.219e+04 0.003 0.998
number -9.622e+00 1.591e+04 -0.001 1.000
offer 1.174e+01 1.084e+04 0.001 0.999
offic -1.344e+01 2.311e+04 -0.001 1.000
one 1.241e+01 6.652e+03 0.002 0.999
onlin 3.589e+01 1.665e+04 0.002 0.998
open 2.114e+01 2.961e+04 0.001 0.999
oper -1.696e+01 2.757e+04 -0.001 1.000
opportun -4.131e+00 1.918e+04 0.000 1.000
option -1.085e+00 9.325e+03 0.000 1.000
order 6.533e+00 1.242e+04 0.001 1.000
origin 3.226e+01 3.818e+04 0.001 0.999
part 4.594e+00 3.483e+04 0.000 1.000
particip -1.154e+01 1.738e+04 -0.001 0.999
peopl -1.864e+01 1.439e+04 -0.001 0.999
per 1.367e+01 1.273e+04 0.001 0.999
person 1.870e+01 9.575e+03 0.002 0.998
phone -6.957e+00 1.172e+04 -0.001 1.000
place 9.005e+00 3.661e+04 0.000 1.000
plan -1.830e+01 6.320e+03 -0.003 0.998
pleas -7.961e+00 9.484e+03 -0.001 0.999
point 5.498e+00 3.403e+04 0.000 1.000
posit -1.543e+01 2.316e+04 -0.001 0.999
possibl -1.366e+01 2.492e+04 -0.001 1.000
power -5.643e+00 1.173e+04 0.000 1.000
present -6.163e+00 1.278e+04 0.000 1.000
price 3.428e+00 7.850e+03 0.000 1.000
problem 1.262e+01 9.763e+03 0.001 0.999
process -2.957e-01 1.191e+04 0.000 1.000
product 1.016e+01 1.345e+04 0.001 0.999
program 1.444e+00 1.183e+04 0.000 1.000
project 2.173e+00 1.497e+04 0.000 1.000
provid 2.422e-01 1.859e+04 0.000 1.000
public -5.250e+01 2.341e+04 -0.002 0.998
put -1.052e+01 2.681e+04 0.000 1.000
question -3.467e+01 1.859e+04 -0.002 0.999
rate -3.112e+00 1.319e+04 0.000 1.000
read -1.527e+01 2.145e+04 -0.001 0.999
real 2.046e+01 2.358e+04 0.001 0.999
realli -2.667e+01 4.640e+04 -0.001 1.000
receiv 5.765e-01 1.585e+04 0.000 1.000
recent -2.067e+00 1.780e+04 0.000 1.000
regard -3.668e+00 1.511e+04 0.000 1.000
relat -5.114e+01 1.793e+04 -0.003 0.998
remov 2.325e+01 2.484e+04 0.001 0.999
repli 1.538e+01 2.916e+04 0.001 1.000
report -1.482e+01 1.477e+04 -0.001 0.999
request -1.232e+01 1.167e+04 -0.001 0.999
requir 5.004e-01 2.937e+04 0.000 1.000
research -2.826e+01 1.553e+04 -0.002 0.999
resourc -2.735e+01 3.522e+04 -0.001 0.999
respond 2.974e+01 3.888e+04 0.001 0.999
respons -1.960e+01 3.667e+04 -0.001 1.000
result -5.002e-01 3.140e+04 0.000 1.000
[ reached getOption("max.print") -- omitted 81 rows ]
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 4409.49 on 4009 degrees of freedom
Residual deviance: 13.46 on 3679 degrees of freedom
AIC: 675.46
Number of Fisher Scoring iterations: 25None of the variables is significant in our logistic regression model.
Note that the logistic regression model yielded the messages algorithm did not converge and fitted probabilities numerically 0 or 1 occurred. Both of these messages often indicate overfitting and the first indicates particularly severe overfitting.
CART model
# Build a CART model
> library(rpart)
> library(rpart.plot)
> spamCART = rpart(spam~., data=train, method="class")
> prp(spamCART)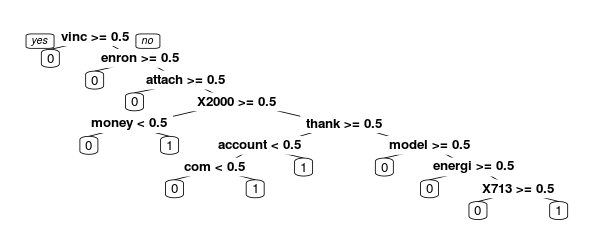
Random Forest model
# Build a random forest model
> library(randomForest)
randomForest 4.6-12
Type rfNews() to see new features/changes/bug fixes.
> set.seed(123)
> spamRF = randomForest(spam~., data=train)Prediction on training data
> predTrainLog = predict(spamLog, type="response")
> predTrainCART = predict(spamCART)[,2]
> predTrainRF = predict(spamRF, type="prob")[,2]
# Evaluate the performance of the logistic regression model on training set
> table(train$spam, predTrainLog > 0.5)
FALSE TRUE
0 3052 0
1 4 954
# training set accuracy of logistic regression
> (3052+954)/nrow(train)
[1] 0.9990025
# training set AUC of logistic regression
> predictionTrainLog = prediction(predTrainLog, train$spam)
> as.numeric(performance(predictionTrainLog, "auc")@y.values)
[1] 0.9999959
# Evaluate the performance of the CART model on training set
> table(train$spam, predTrainCART > 0.5)
FALSE TRUE
0 2885 167
1 64 894
# training set accuracy of CART
> (2885+894)/nrow(train)
[1] 0.942394
# training set AUC of CART
> library(ROCR)
> predictionTrainCART = prediction(predTrainCART, train$spam)
> as.numeric(performance(predictionTrainCART, "auc")@y.values)
[1] 0.9696044
# Evaluate the performance of the random forest model on training set
> table(train$spam, predTrainRF > 0.5)
FALSE TRUE
0 3013 39
1 44 914
# training set accuracy of random forest
> (3013+914)/nrow(train)
[1] 0.9793017
# training set AUC of random forest
> predictionTrainRF = prediction(predTrainRF, train$spam)
> as.numeric(performance(predictionTrainRF, "auc")@y.values)
[1] 0.9979116In terms of both accuracy and AUC, logistic regression is nearly perfect and outperforms the other two models.
Prediction on testing data
predTestLog = predict(spamLog, newdata=test, type="response")
predTestCART = predict(spamCART, newdata=test)[,2]
predTestRF = predict(spamRF, newdata=test, type="prob")[,2]
# Evaluate the performance of the logistic regression model on testing set
> table(test$spam, predTestLog > 0.5)
FALSE TRUE
0 1257 51
1 34 376
> (1257+376)/nrow(test)
[1] 0.9505239
> predictionTestLog = prediction(predTestLog, test$spam)
> as.numeric(performance(predictionTestLog, "auc")@y.values)
[1] 0.9627517
# Evaluate the performance of the CART model on testing set
> table(test$spam, predTestCART > 0.5)
FALSE TRUE
0 1228 80
1 24 386
> (1228+386)/nrow(test)
[1] 0.9394645
> predictionTestCART = prediction(predTestCART, test$spam)
> as.numeric(performance(predictionTestCART, "auc")@y.values)
[1] 0.963176
# Evaluate the performance of the random forest model on testing set
> table(test$spam, predTestRF > 0.5)
FALSE TRUE
0 1290 18
1 25 385
> (1290+385)/nrow(test)
[1] 0.9749709
> predictionTestRF = prediction(predTestRF, test$spam)
> as.numeric(performance(predictionTestRF, "auc")@y.values)
[1] 0.9975656The random forest outperformed logistic regression and CART in both measures, obtaining an impressive AUC of 0.997 on the test set.
The logistic regression model obtained nearly perfect accuracy and AUC on the training set and had far-from-perfect performance on the testing set. This is an indicator of overfitting. A logistic regression model with a large number of variables is particularly at risk for overfitting.
Most of the email providers move all of the emails flagged as spam to a separate “Junk Email” folder, meaning those emails are not displayed in the main inbox. Many users never check the spam folder, so they will never see emails delivered there.
A false negative is largely a nuisance (the user will need to delete the unsolicited email). However, a false positive can be very costly, since the user might completely miss an important email due to it being delivered to the spam folder. Therefore, the false positive is more costly.
Nevertheless, it may be the case that a user who is particularly annoyed by spams would assign a particularly high cost to a false negative. While, users who never check spam folder will miss the email, incurring a particularly high cost to false positive. Thus, a large-scale email provider need to automatically collect information about how often each user accesses his/her Junk Email folder to infer preferences. That’s what most email providers do.
Footnotes:
1: Email spam ↩
2: “Spam Filtering with Naive Bayes – Which Naive Bayes?” by V. Metsis, I. Androutsopoulos, and G. Paliouras ↩
Comments