The multimodal models that can learn from both image and text are called Vision Language Models (VLM). The Vision Language Modeling can be divided into the following non-mutually exclusive paradigms.
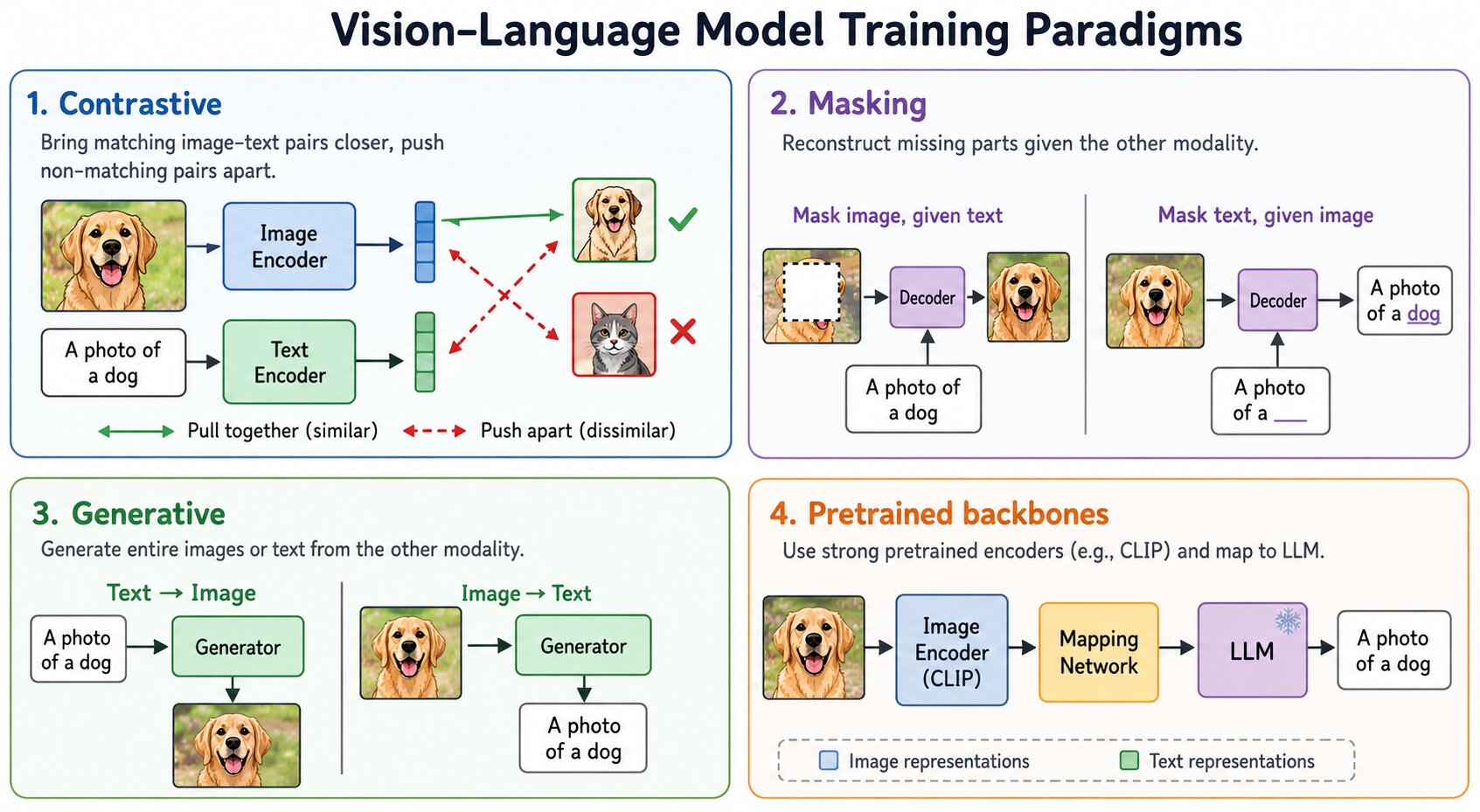
1. Contrastive training
In contrastive training, we train models using a dataset that contains pairs of positive and negative examples. The VLM’s job is to learn the representation: similarity between positive pairs and dissimilarity between negative pairs. The models like CLIP come in this category.
1.1. CLIP: Contrastive Language–Image Pre-Training
Trained on 400m image-text pairs, CLIP (Contrastive Language–Image Pre-Training) is a model, released by OpenAI in Jan 2021, that learns visual concepts from natural language supervision.
While standard image models jointly train an image feature extractor and a linear classifier to predict some label, CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, text) training examples. At test time the learned text encoder synthesizes a zero-shot linear classifier by embedding the names or descriptions of the target dataset’s classes.
Shared Representation Space CLIP learns to represent both images and text in a common embedding space, allowing for direct comparison and retrieval.
Contrastive Learning The model uses a contrastive learning objective to align text and image embeddings. This means it learns to bring together the embeddings of matching text-image pairs and push apart those of non-matching pairs.
Zero-Shot Learning CLIP can perform tasks without task-specific training by leveraging its understanding of the relationships between text and images.
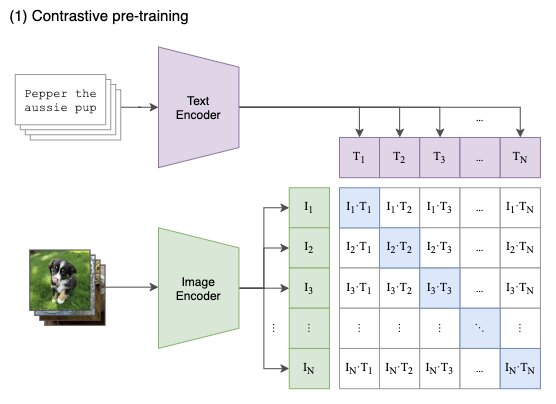
Architecture
Image Encoder Typically a Vision Transformer (ViT) or a convolutional neural network (e.g., ResNet) that converts images into fixed-size embeddings.
Text Encoder Usually a transformer-based model (e.g., a modified GPT) that converts text descriptions into fixed-size embeddings.
Training vs Inference
- During training, it tries to maximize the cosine similarity between correct image-caption vector pairs, and minimize the similarity scores between all incorrect pairs.
- During inference, it calculates the similarity scores between the vector of a single image with a bunch of possible caption vectors, and picks the caption with the highest similarity. Note that CLIP is not a caption generation model, it can only tell you if some existing text caption fits well with an existing image or not.
Working
Image Embeddings
For every image in the batch, the Image Encoder computes an image vector (I1, I2, …). Each vector is of size de (latent dimension). Output: N×de matrix.
Text Embeddings
Textual descriptions are squashed into text embeddings [‘T1’,’T2’,...,’TN’], producing a N×de matrix.
Pairwise Similarities
Multiply the two matrices to calculate pairwise cosine similarities between every image and text description. Output: N×N matrix.
Contrastive Objective
Maximize cosine similarity along the diagonal (correct pairs). Off-diagonal similarities are minimized — I1 matches T1, not T2, T3, etc.
Contrastive Loss
CLIP employs a symmetric cross-entropy loss over the similarity scores computed for each pair within a batch. The contrastive loss is computed using the cross-entropy loss for both the image-to-text and text-to-image directions. This ensures that the correct image-text pairs have high similarity while incorrect pairs have low similarity. Apply the softmax function to the similarity scores to convert them into probabilities. This is done separately for the rows and columns of the similarity matrix to handle both image-to-text and text-to-image matching.
- Image-to-text similarity (row-wise): \(P_{ij} = \frac{\exp(S_{ij}/\tau)}{\sum_{k=1}^{N} \exp(S_{ik}/\tau)}\) The image-to-text direction measures how well the model can predict the correct text given an image.
- Text-to-image similarity (column-wise): \(Q_{ij} = \frac{\exp(S_{ij}/\tau)}{\sum_{k=1}^{N} \exp(S_{kj}/\tau)}\) The text-to-image direction measures how well the model can predict the correct image given a text.
where τ is a temperature parameter that controls the sharpness of the softmax distribution.
The total loss is the average of the two cross-entropy losses:
\[L_{contrastive} = \frac{1}{2N} \sum_{i=1}^{N} [-\log P_{ii}] + \frac{1}{2N} \sum_{j=1}^{N} [-\log Q_{jj}]\]# CLIP code
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2Zero-Shot Image Classification
CLIP can classify images into categories it was not explicitly trained on. By providing text descriptions of categories, CLIP can match the image to the appropriate category based on its learned representations.
CLIP can be used to retrieve relevant images given a text query and vice versa. This is useful for search engines and content-based image retrieval systems.
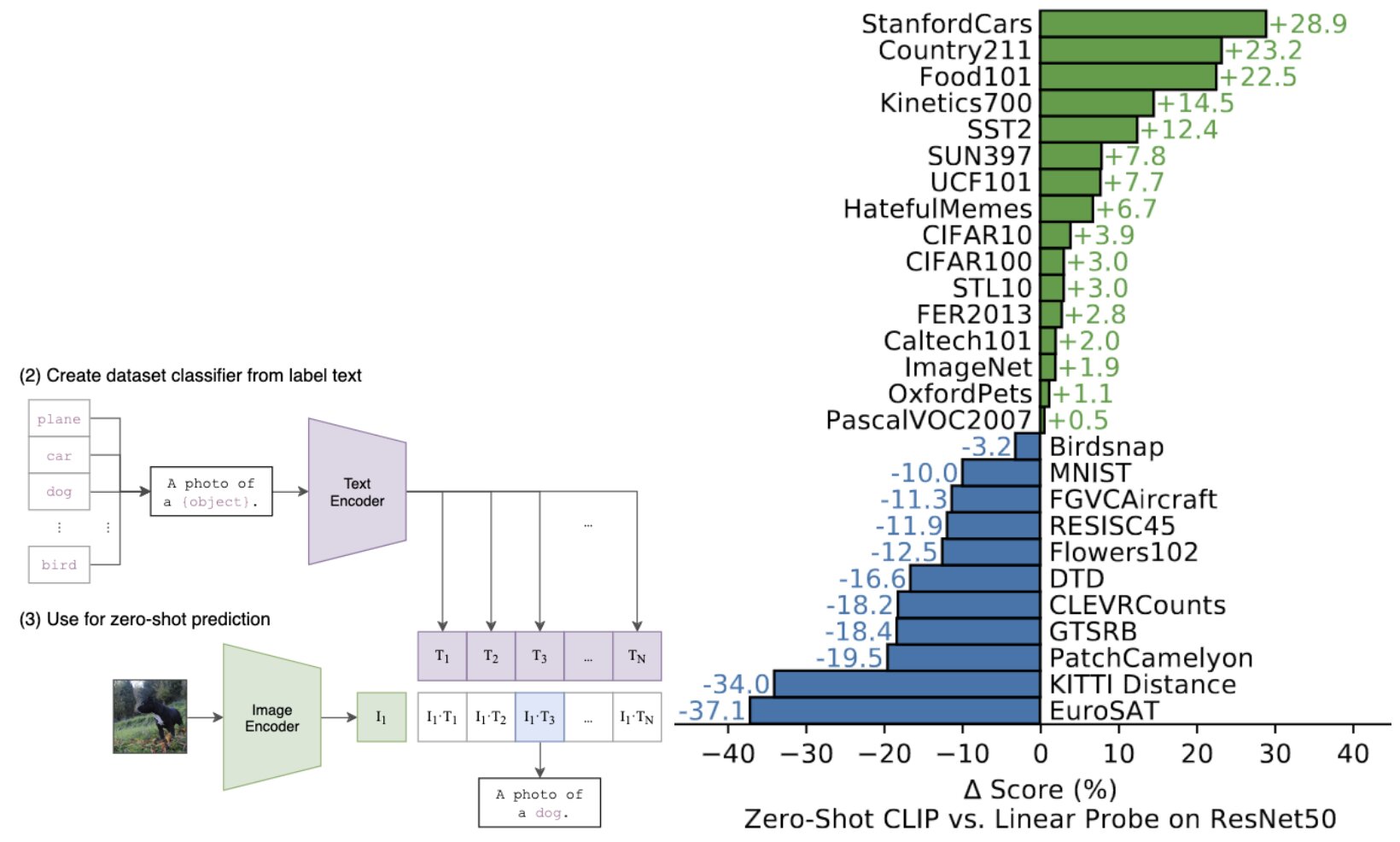
Across a 27 dataset eval suite, a zero-shot CLIP classifier outperforms a fully supervised linear classifier fitted on ResNet-50 features on 16 datasets, including ImageNet.
Linear probe means that only a linear classifier (last layer) is trained while keeping the pre-trained features of layers constant.
Prompt Engineering
Prompt engineering in the context of CLIP refers to the careful design of textual inputs (prompts) used during the zero-shot classification task, which improves CLIP performance.
Contextual Prompts: Instead of using simple class names, more descriptive and context-rich sentences are used. For example, instead of just “dog”, the prompt might be “a photo of a dog” or “an image of a dog in the park”.
Compared to the baseline of using contextless class names, prompt engineering and ensembling boost zero-shot classification performance by almost 5 points on average across 36 datasets. This improvement is similar to the gain from using 4 times more compute with the baseline zero-shot method but is “free” when amortized over many predictions.
Cons
Polysemy CLIP cannot differentiate between two words due to lack of context. For example, the word ‘boxer’ can appear as a dog breed or an athlete. Perhaps a better set of data could help here.
Handwriting detection While CLIP is excellent at understanding complex images, it still struggles with tasks such as handwriting detection (especially handwritten digits). This can be due to lack of sufficient data during training.
2. Masking
In masking, as the name suggests, we mask (hide) the portion of image or text during training.
- In Masked Language Modeling (MLM) as used in BERT, the tokens are masked to train the model.
- In Masked Image Modeling (MIM), the image patches are masked to train the model.
Wrt VLMs, we can either
- Mask image patches and keep the text captions unmasked, or
- Mask text and keep the image unmasked, or
- Mask both image and text.
Implementing masking is straightforward for transformer based models, since the input is tokenized, we can easily drop the tokens to be masked during training.
2.1. FLAVA (Foundational Language And Vision Alignment Model)
FLAVA uses masking for both image and text encoders. It tries to be a universal model that targets all combination of image and text modalities to solve vision tasks, language tasks, and cross- and multi-modal vision and language tasks.
Architecture
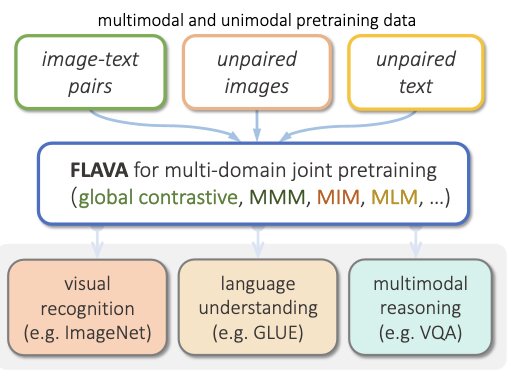
Its architecture consists of
Vision Transformer (ViT)
Encodes images into patches for linear embedding, along with a classification token (CLS_I).
Transformer-based text encoder
Gives vector embeddings for tokenized text input and also output hidden state vectors along with a classification token (CLS_T).
Multimodal encoder
Combines visual and textual information. It fuses hidden states from both image and text encoders, utilizing cross-attention mechanisms within transformer to integrate visual and textual information, and gives additional multimodal classification token (CLS_M).
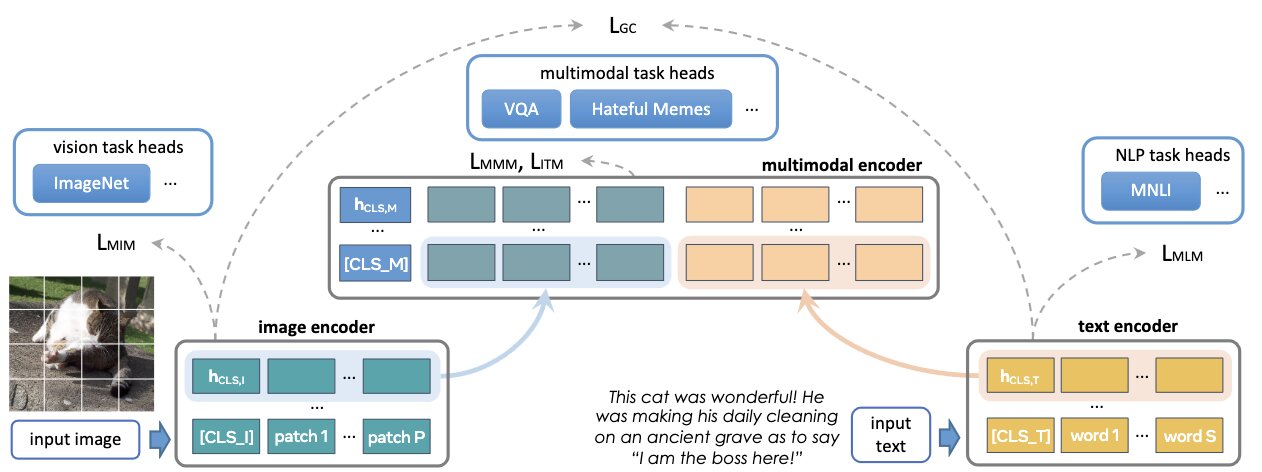
During pretraining, masked image modeling (MIM) and mask language modeling (MLM) losses are applied onto the image and text encoders over a single image or a text piece, respectively, while contrastive, masked multimodal modeling (MMM), and image-text matching (ITM) loss are used over paired image-text data. For downstream tasks, classification heads are applied on the outputs from the image, text, and multimodal encoders respectively for visual recognition, language understanding, and multimodal reasoning tasks.
3. Generative VLMs
Unlike the previous approaches that can do partial reconstructions, generative VLMs can generate entire images or long captions. They are also more expensive to train.
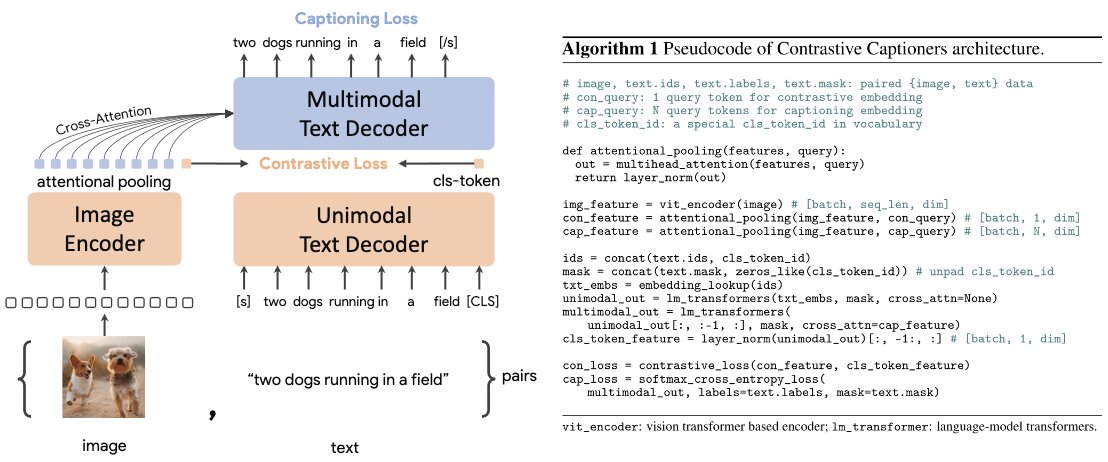
3.1. CoCa (Contrastive Captioners)
CoCa integrates both contrastive and generative losses to improve multimodal understanding and generation. The generative loss corresponds to the captions generated by a multimodal text decoder, which takes the outputs of an image encoder and a unimodal text decoder. The new loss allows the ability to perform new multimodal understanding.
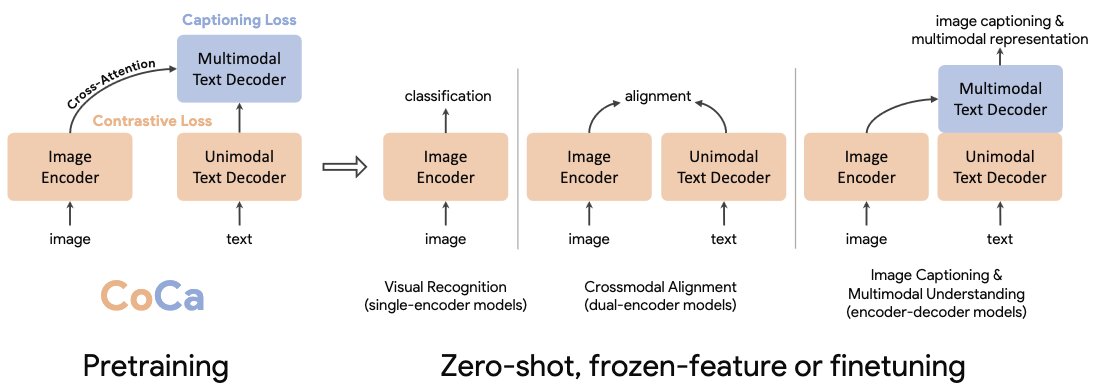
CoCa is pretrained using datasets like ALIGN (with around 1.8 billion images and alt-text pairs) and JFT-3B (containing over 29.5k classes treated as alt-text).
The pretrained CoCa can be used for downstream tasks including visual recognition, vision-language alignment, image captioning and multimodal understanding with zero-shot transfer, frozen-feature evaluation or end-to-end finetuning.
3.2. CM3leon and Chameleon
It’s a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence.
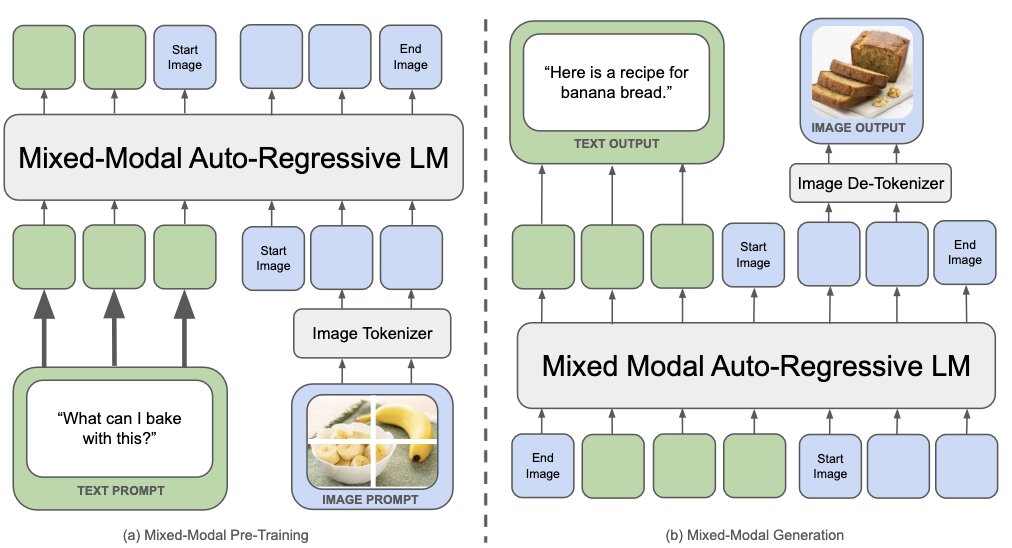
CM3leon (released before Chameleon) uses a transformer-based architecture that processes interleaved text and image tokens.
The tokenization approach allows the model to handle mixed sequences of textual and visual content effectively. CM3leon uses an image tokenizer that encodes a 256x256 image into 1024 tokens from a vocabulary of 8192. It also uses a text tokenizer with a vocabulary size of 56320. A special token <break> indicates transitions between modalities. The tokenized images and texts are processed by a decoder-only transformer model, enabling the model to handle sequences of both image and text tokens without needing separate encoders for each modality.
Training Process
Retrieval-Augmented Pretraining A CLIP-based encoder acts as a dense retriever to fetch relevant multimodal documents, prepended to the input sequence. Trained using next-token prediction, increasing data efficiency.
Supervised Fine-Tuning (SFT) Multi-task instruction tuning, allowing the model to process and generate content across different modalities. Significantly improves text-to-image generation and language-guided image editing.
Chameleon builds on CM3leon. Its architecture largely follows LLaMa-2.
3.3. Generative Text-to-Image Models
Models like Stable Diffusion and Imagen are trained to generate images from text prompts. While these models primarily focus on image generation, their ability to learn the joint distribution between text and images makes them suitable for various vision-language tasks.
These models can generate high-quality images based on textual descriptions, demonstrating the potential of generative approaches in understanding and creating visual content from textual inputs.
4. Pretrained backbones based VLMs
Since VLMs are expensive to train, these types of models leverage open-source LLMs like Llama to learn a mapping between an image encoder (which could also be pre-trained) and the LLM. This avoid the hefty cost to train VLM.
Pretrained Backbones Utilize large language models (LLMs) and vision encoders that have already been trained on extensive datasets.
Mapping Mechanism Learn a mapping between the visual and textual representations produced by these pretrained models, thereby enabling multimodal understanding and generation with reduced computational resources.
4.1. Frozen
It connects vision encoders to frozen language models via mapping layers which project visual features to text token embeddings. It was the first model to use a pretrained LLM for VLM task.
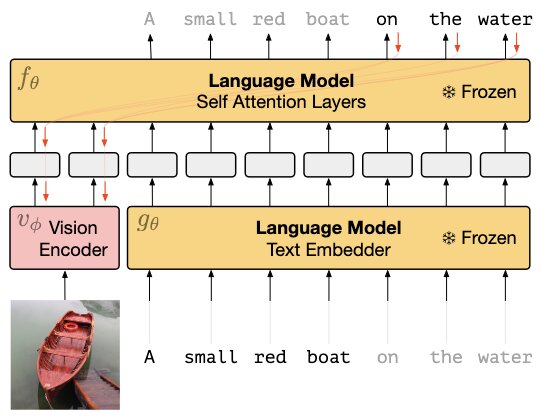
In Frozen, the language model (a 7 billion-parameter transformer trained on C4) is kept frozen (to maintain features that pre-trained model had already learned), while the vision encoder (NF-ResNet-50) and the linear mapping are trained from scratch. The vision embeddings are added as visual prefix to language embeddings - this fine-tuning for image captioning only updates weights of vision encoder.
Catastrophic forgetting: Fine-tuning Language Model results in model forgetting its general capabilities and only getting good at fine-tuned tasks. Frozen address this problem by keeping the Language Model frozen and only training Vision Encoder.
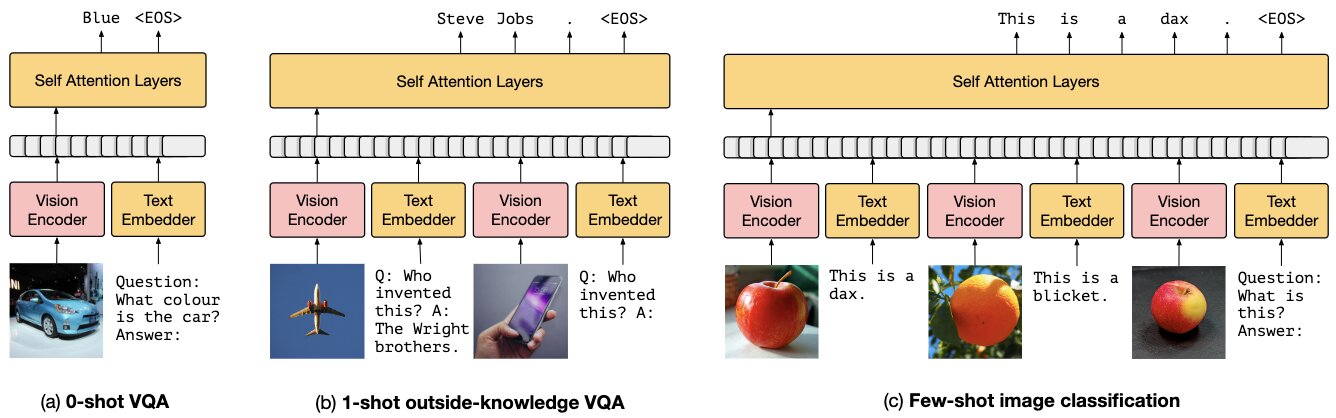
Frozen exhibits good zero-shot and few-shot performance on multimodal tasks e.g. visual question answering (VQA). At inference time, the language model can be conditioned on interleaved text and image embedding.
4.2. MiniGPT
MiniGPT-4 accepts text input and image input, and it only produces text output. A linear projection layer is used to align image representation (using the same visual encoder in BLIP-2, which is based on Q-Former and a ViT backbone) with the input space of the Vicuna language model.
Given that the visual encoder and Vicuna language model are already pretrained and used as from prior work, MiniGPT-4 requires only training the linear project layer which is done in two rounds.
Feature Alignment Train the linear projection layer using image-text pairs.
Instruction Tuning Fine-tune using highly-curated data in an instruction-tuning format.
MiniGPT-5 extends MiniGPT-4 so that the output can contain text interleaved with images.
To generate images as well, MiniGPT-5 used generative tokens which are special visual tokens that can be mapped (through transformer layers) to feature vectors, which in turn can be fed into a frozen Stable Diffusion 2 model. The authors used supervised training on downstream tasks (e.g., multi-modal dialogue generation and story generation).
4.3. BLIP-2
It integrates vision encoders (e.g., CLIP) with large language models via a Q-Former module. Q-Former is a transformer that interacts with image embeddings through cross-attention and projects them to the LLM’s input space. It greatly reduces training time by leveraging pretrained, frozen models for both vision and language tasks.
4.4. Qwen-VL and Qwen-VL-Chat
It combines a ViT-bigG visual encoder with a one-layer cross-attention module to compress visual representations into a sequence fed into the Qwen-7B language model. It’s designed for tasks requiring detailed multimodal interaction, such as visual question answering and interactive chatbots.
4.5. LLaVA (Large Language-and-Vision Assistant)
LLaVA is a vision-language model designed to enhance multimodal chat capabilities through instruction fine-tuning.
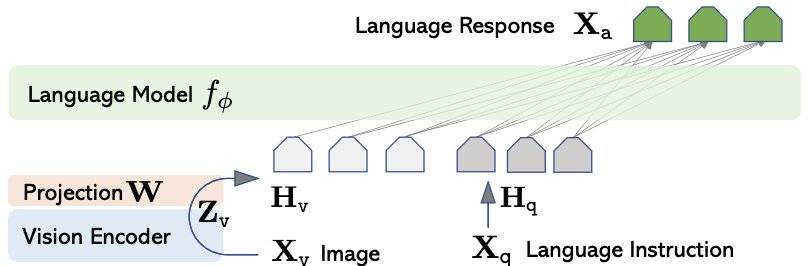
Its architecture consists of
Language Model Pre-trained Vicuna (created by fine-tuning LLaMa 2 on conversations).
CLIP Vision Encoder (ViT-L/14) Used for extracting visual features from images. CLIP aligns visual and textual representations.
It involves passing the image through vision encoder and passing text embeddings as it is, combining them through Linear projection layer then passing them through Language Model. The outputs from language model and vision encoder are combined into the same dimensional space using a linear projector (linear layer). This integration allows the model to handle multimodal inputs effectively.
Multimodal instruction tuning

- Few-shot prompts to generate dataset: Take COCO image captioning dataset, and create instruction-dataset using GPT prompts. Ask text-only GPT to generate 3 types of responses (conversation, detailed description, complex reasoning).
- The top block shows the contexts such as captions and boxes used to prompt GPT, and the bottom block shows the three types of responses. Note that the visual image is not used to prompt GPT, we only show it here as a reference.
Training
Its training consists of two stages.
Pre-training for Feature Alignment Keep both the visual encoder and LLM weights frozen. Train only the Linear projection layers.
Fine-tuning End-to-End Keep the visual encoder frozen. Fine-tune the Linear projector layer and Language model weights end-to-end.
Catastrophic forgetting doesn’t happen here even though we’re fine-tuning Language Model because our dataset is mulit-instruction tuned. Instruction tuning is one of the solutions of catastrophic forgetting. This approach is designed to enhance the model’s flexibility and generalization capabilities by exposing it to a diverse range of tasks during the training phase. The goal is to produce a model that can adapt more effectively to a variety of tasks post-training, even those not seen during training, reducing the risk of catastrophic forgetting by reinforcing a broad base of capabilities.
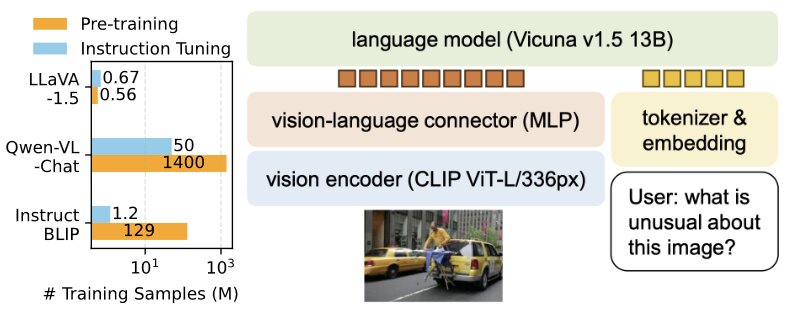
LLaVA-1.5 improves on LLava’s instruction fine-tuning by using a cross-modal fully connected multi-layer perceptron (MLP) layer and incorporating academic VQA instruction data.
4.6. Frozen Transformers in Language Models
The large language models (LLMs) trained solely on text data are good encoders for visual tasks thus allowing usage of frozen language models. A straightforward method of using a frozen transformer block from pre-trained LLMs as a visual encoder layer is as follows.
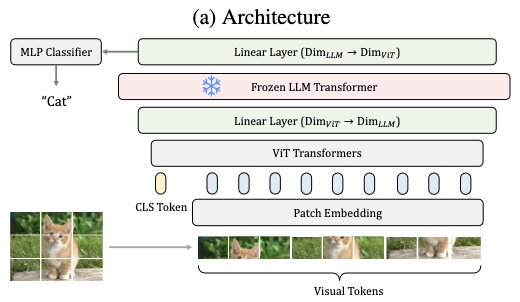
def __init__(self, *args, **kawargs):
# Encoder
self.ViT = Encoder(args, kwargs)
self.classifier = Decoder(args, kwargs)
# Language Transformer
self.L1 = nn.Linear(ViT.hidden_dim, LM.hidden_dim)
self.LM = LM_Transformer(args, kwargs)
self.L2 = nn.Linear(LM.hidden_dim, ViT.hidden_dim)
# Freezing
for param in self.LM.parameters():
param.requires_grad = False
def forward(self, img):
z = self.ViT(x)
z = self.L1(z)
z = self.LM(z)
z = self.L2(z)
y = self.classifier(z)
return yQUIZ: Test Your Knowledge
References and Image sources:
- An Introduction to Vision-Language Modeling
- CLIP (Contrastive Language–Image Pre-Training)
- FLAVA (Foundational Language And Vision Alignment Model)
- CoCa (Contrastive Captioners are Image-Text Foundation Models)
- Chameleon: Mixed-Modal Early-Fusion Foundation Models
- Frozen (Multimodal Few-Shot Learning with Frozen Language Models)
- LLaVA (Visual Instruction Tuning)
- LLaVA 1.5 (Improved Baselines with Visual Instruction Tuning)
- Frozen transformers in Language Models are effective visual encoder layers


Comments