While Large Language Models (LLMs) are revolutionary, they sometimes get it wrong like citing varying figures for something as critical as Tesla’s total assets on a given date. In the accompanying figure, you can see ChatGPT4 giving different results when asked the same question multiple times. This problem is called LLM hallucinations. And that’s where Retrival Augmented Generation (RAG) comes in. In this blog post, I’ll describe how to create a Chabot for 10Q Financial Reports that leverages RAG.

What is Retrival Augmented Generation (RAG)?
It’s a framework that combines the strengths of information retrieval and generative language modeling to enhance the capabilities of machine learning systems, particularly in tasks that involve natural language understanding and generation. It involves two main components.
Retrieval Component responsible for accessing an external knowledge source, such as a database or a document collection, to retrieve relevant information based on the input query.
Generation Component leverages LLMs to generate response based on the context provided by the retrieval component.
RAG vs Fine Tuning
Fine tuning updates the model’s weights by training further on domain-specific data, baking knowledge into the parameters. This works well when you need the model to adopt a specific tone or domain expertise. However, fine-tuning is expensive, and it can’t incorporate new information without another training run, and offers no attribution i.e. the model can’t show which document it used.
RAG, by contrast, keeps the LLM’s weights frozen. Knowledge lives in an external vector database that can be updated instantly: add new documents or remove outdated ones without touching the model. Every answer is grounded in retrieved context, providing transparent attribution and lowering hallucination risk.
For quarterly financial reports, RAG is the natural choice, data changes every 90 days, users need answers backed by specific filings, and retraining each quarter would be impractical.
Vector Database
Think of a traditional database as a spreadsheet, it stores rows and columns of structured data like names, dates, and numbers, and you query it with exact matches (e.g., “find the row where company = 'Tesla'”). A vector database is fundamentally different: instead of rows and columns, it stores data as points in a high-dimensional vector space, where similar items cluster closer together.
Imagine a map of a city. On a regular map, nearby locations are physically close. A vector database works the same way, except the “locations” are mathematical vectors (lists of numbers) that represent the meaning of your data. Documents about “Tesla’s revenue” end up near each other, while documents about “Apple’s iPhone sales” cluster elsewhere. When you ask a question, the database converts your query into a vector and finds the points nearest to it on the map, returning the most semantically relevant results.
This approach excels at handling unstructured data like text, images, and audio, where exact keyword matching falls short.
Creating a Vector Database: A large document is split into smaller chunks. Each chunk is passed through an embedding model (like Sentence Transformers) that converts it into a high-dimensional vector, essentially a semantic “address” in the vector space. These vectors are stored in the database.
Indexing: Storing millions of vectors means finding neighbors by brute force (comparing against every single one) would be too slow. Before querying, the database builds an index, a data structure that organizes the vectors so similar ones can be found in milliseconds.
Querying a Vector Database: When a user asks a question:
- The query is embedded into a vector using the same embedding model.
- The database searches its index for n closest vectors using distance metrics like cosine similarity.
- The original text chunks corresponding to those nearest vectors are retrieved as context for LLM.
The full lifecycle looks like this:
- The embedding model creates vector embeddings for each text chunk we want to index.
- Each vector embedding is stored in the database alongside a reference to its original content.
- When the application issues a query, the same embedding model converts the query into a vector.
- The database finds stored vectors closest to the query vector and returns their associated content.
RAG Architecture
The full RAG pipeline connects four components: ingestion, storage, retrieval, and generation, into a single flow:

The ingestion pipeline runs offline: documents are loaded, split into chunks, embedded, and stored in the vector database. The query pipeline runs at inference time: a user question is embedded with the same model, the vector DB retrieves the nearest chunks, and the LLM generates a grounded answer using the prompt template.
Building RAG Chatbot
Dataset
The dataset primarily consists of financial documents, specifically 10-Q and 10-K filings from major publicly traded companies, such as Tesla, NVIDIA, and Apple. These documents are obtained from the U.S. Securities and Exchange Commission’s (SEC) EDGAR database, which is a reliable source for such financial reports. Each 10-Q and 10-K filing within the dataset contains a comprehensive overview of a company’s financial performance.

Steps
We need to following the following steps to build a RAG Chatbot.
- Problem statement: Given a PDF document and a query, retrieve the relevant details and information from the document as per the query, and synthesize this information to generate accurate answers.
- Data Ingestion and Processing: Reading PDFs of financial reports and split the documents for efficient text chunking of long documents.
- Retrieval-Augmented Generation (RAG): Combination of document retrieval with the generative capabilities of the chosen language models.
- Large Language Models: Evaluation of various models, including GPT-3.5-turbo, LLama 2, Gemma 1.1, etc.
- Conversation Chain and Prompt Design: Crafting of a prompt template designed for concise two-sentence financial summaries.
- User interface: Designing Chatbot like user interface.
First, we load the 10-Q PDF using PyPDFLoader.
from langchain.document_loaders import PyPDFLoader
# create a loader
loader = PyPDFLoader(r"data/tsla-20230930.pdf")We then split data in chunks using a recursive character text splitter to handle large documents.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=300)
all_splits = text_splitter.split_documents(data)Chunking Strategy Tradeoffs
The chunk_size=500 and chunk_overlap=300 parameters control how the document is sliced. Choosing these values involves tradeoffs:
Smaller chunks (e.g., 200 tokens) keep each chunk focused on a single topic, which improves retrieval precision, the query is more likely to match a tightly relevant snippet. However, the LLM may lack surrounding context to understand financial tables or multi-sentence figures. The risk is retrieving fragments that are individually relevant but miss the bigger picture (e.g., getting “total assets: $87B” without the reporting period).
Larger chunks (e.g., 1000+ tokens) provide richer context, helping the LLM interpret numbers, tables, and cross-references within a single chunk. But they dilute relevance, a chunk covering an entire “Liquidity” section might be retrieved for a query about “cash equivalents” even if only one sentence is relevant, introducing noise into the LLM’s context window.
The optimal chunking balances context preservation with retrieval precision. A chunk overlap of 300 ensures that sentences or table rows split across chunk boundaries appear in at least two chunks, preventing information loss at cut points. This is especially important for financial documents where a table’s header row might end up in chunk N while its data rows fall in chunk N+1.
We now create the embeddings using Sentence Transformer and HuggingFace embeddings. In order to create vector embeddings, we use the open-source Chroma vector database.
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs={"device": "cuda"})
vectordb = Chroma.from_documents(documents=all_splits, embedding=embeddings, persist_directory="chroma_db")We use HuggingFace to load LLama 2 model and create a HuggingFace pipeline. Since, we’re going to use LangChain, we use HugggingFacePipeline wrapper from LangChain to create LangChain llm object, which we’re going to use to do further processing.
import transformers
from transformers import LlamaForCausalLM, AutoTokenizer, AutoConfig
from langchain.llms import HuggingFacePipeline
model_config = AutoConfig.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf",
trust_remote_code = True, config = model_config, device_map = 'auto')
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
# Creating Pipeline
query_pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",)
llm = HuggingFacePipeline(pipeline=query_pipeline)If we want to use GPT models from OpenAI, we can diretly use openai API.
import os
import openai
from langchain.chat_models import ChatOpenAI
# Set your OpenAI API key
openai.api_key = os.getenv("OPENAI_API_KEY")
# Define LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)Finally, we create a LangChain chain for our RAG system. We also pass a task-specific prompt to guide LLM for question answering wrt RAG for financial reports.
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
# Define prompt template
template = """You are an assistant for question-answering tasks for Retrieval Augmented Generation system for the financial reports such as 10Q and 10K.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use two sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
retriever = vectordb.as_retriever()
# Setup RAG pipeline
conversation_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)Finally, we invoke our conversation chain on user input.
user_input = "What's the total assets of Tesla?"
output = conversation_chain.invoke(user_input)We can integrate our code with some frontend e.g. with Dash to have chatbot like interface.
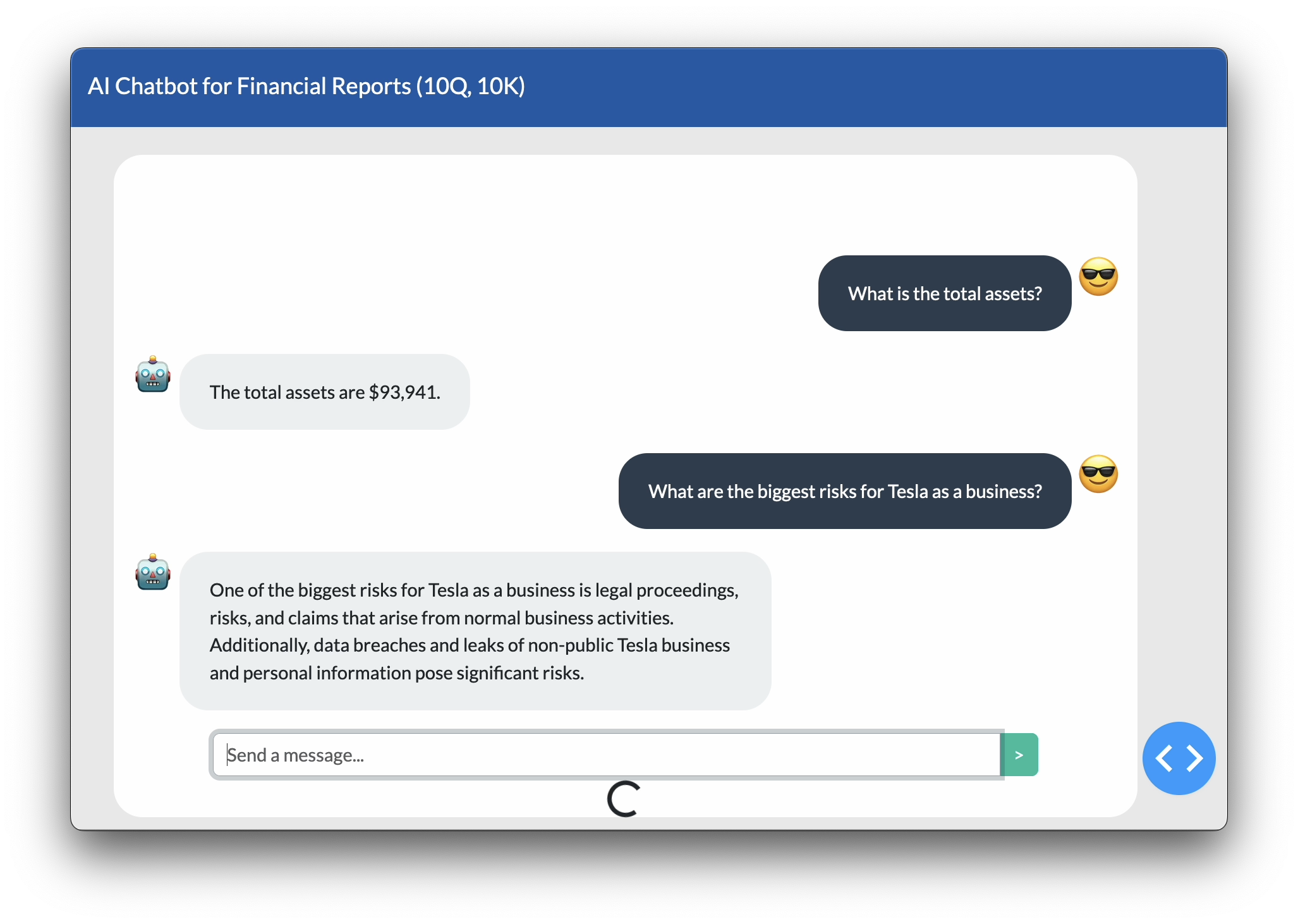
The full code is availble at https://github.com/kHarshit/Financial_Document_Summarization_through_RAG
Evaluation Metrics
A RAG pipeline requires evaluation at both the retrieval and generation steps.
Retrieval Metrics
The first part of a RAG pipeline is retrieval where the system needs to fetch relevant information from vector database.
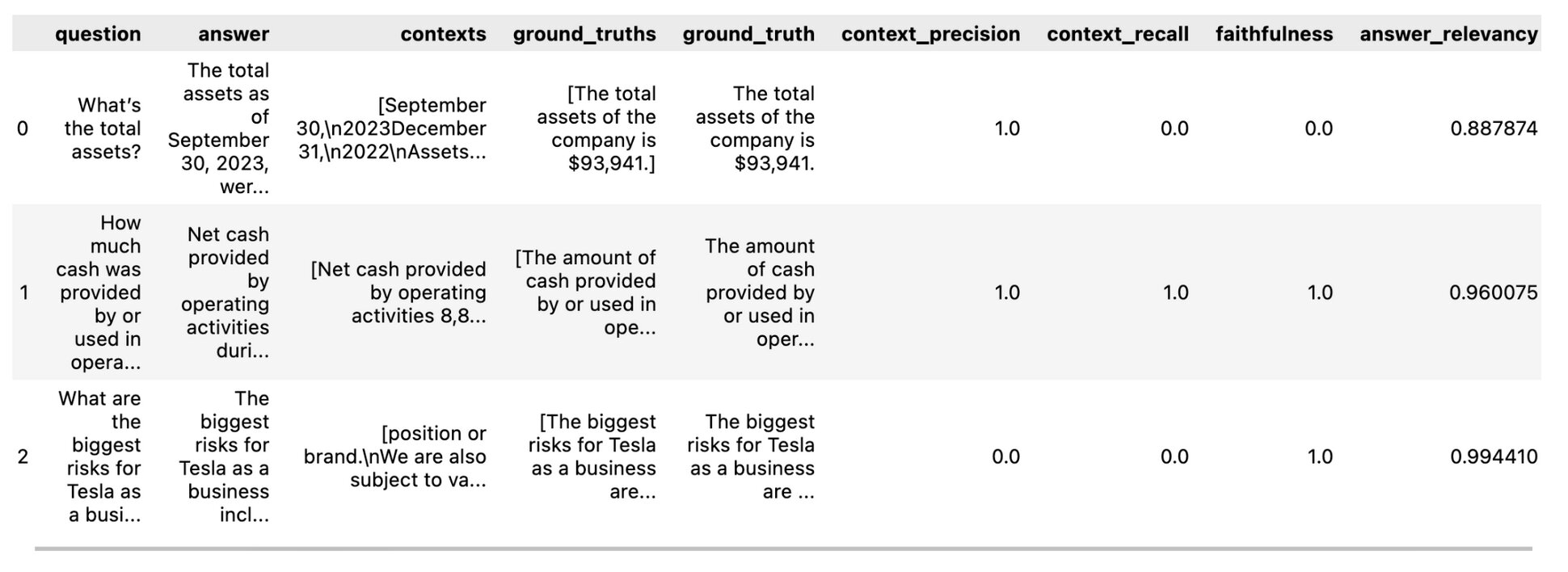
Context Recall checks whether the system retrieved all the important information needed to answer the question. It measures how much the retrieved context aligns with the annotated answer which is treated as ground truth.
Context Precision measures whether the retrieved context is actually relevant i.e. Out of all the chunks retrieved, how many are actually relevant to the question?
Generation Metrics
After retrieval, the language model generates the final response.
Answer Relevancy measures how relevant answer is wrt question. A technically correct answer can still be poor if it doesn’t answer the question.
For example, if the user asks “What was Apple’s net income?”. A relevant answer should provide the figure, the reporting period, and source context, not a long summary of Apple’s entire financial performance.
Faithfulness measures whether the generated answer is supported by the provided context. It checks that every claim in the answer can be traced back to the retrieved context i.e., the model stayed grounded.
For example, the model might say “revenue increased due to higher product deliveries” when the retrieved context only says revenue increased, without mentioning deliveries. The extra causal claim is unfaithful.


Comments