← Blog
All Categories →
CUDA
GPU programming and CUDA for high-performance computing covering parallel programming, memory hierarchies, and optimizing compute-heavy workloads like matrix multiplication.
2 posts
-
 CUDA
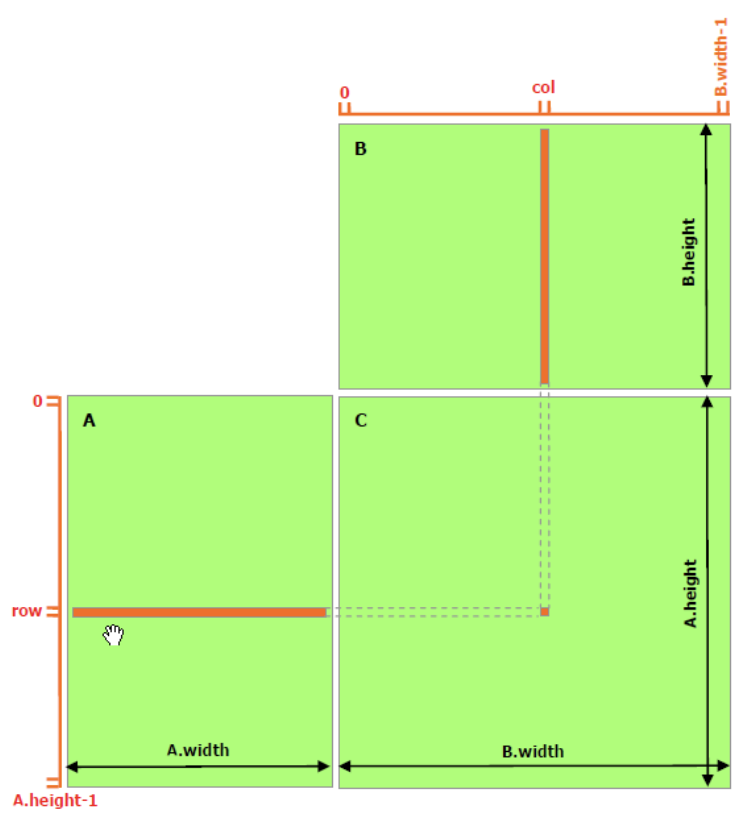
CUDAMatrix Multiplication in CUDA
Implementing matrix multiplication in CUDA from a naive CPU baseline to GPU-accelerated versions using tiled shared memory for deep learning workloads.
-
 Deep Learning
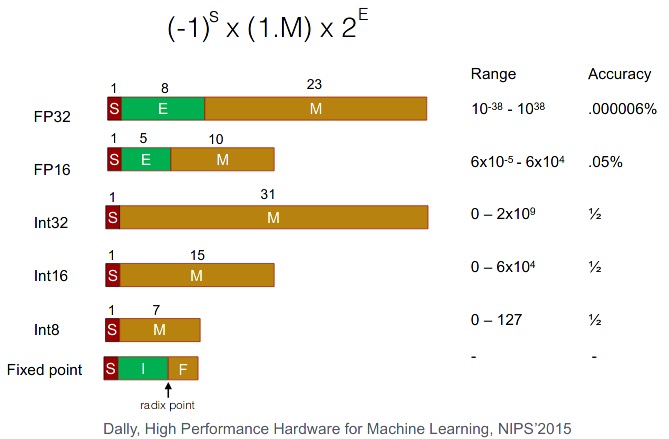
Deep LearningMixed Precision and Quantization: Accelerating Deep Learning Training and Inference
Comprehensive guide to mixed precision training (FP16/FP32) and INT8 quantization, covering GPU architecture, Tensor Cores, loss scaling, AMP, PTQ, QAT, and layer fusion with practical code examples.