How do you compare and benchmark Frontier AI models? Building fair and meaningful tests for AI turns out to be surprisingly hard with the evolving capabilities of models.
This blog post outlines the AI evaluation benchmark landscape, what each benchmark measures, how fast it is saturating, and where the frontier AI stands today.
What is a Benchmark?
A benchmark is a standardized test used to measure how well a model performs on a specific task. Just as students take exams to assess knowledge, AI models are run through benchmarks to measure their capabilities.
“Frontier models” refers to the most capable AI systems currently available e.g. GPT-5.6, Claude Fable 5, Gemini 3.1 Pro, Grok 4, etc. Evaluating these models requires progressively harder tests. When every model aces a test, that test no longer tells you anything useful i.e. it has saturated. The field then moves to a harder benchmark, and the cycle repeats.
What Benchmarks Actually Measure
Not all benchmarks test the same thing. Before looking at specific evaluations, it helps to understand the capability domains they cover, because a model that excels at one may fall short at another.
Knowledge & Factual Reasoning
Does the model know things, and can it apply that knowledge? These tests range from broad general knowledge across dozens of subjects to deep, PhD-level questions in science and mathematics.
Key signal: A model can score well on broad knowledge tests by memorizing facts, while still failing at questions that require genuine reasoning and analysis.
Mathematical & Logical Reasoning
Can the model work through multi-step problems without making errors along the way? Tests range from grade-school word problems to competition mathematics and open research problems.
Key signal: Models that struggle here tend to make silent arithmetic or logic errors in real-world multi-step tasks.
Coding & Software Engineering
Can a model write, debug, and navigate real codebases? For example, replicating the behavior of a software engineer, a model is asked to produce a working fix for a bug report given the model an entire codebase.
Key signal: The gap between “can write code” and “can fix a real bug in a large codebase” is significant, and this is where models still differ meaningfully.
Agentic & Tool-Use Capability
Can the model take actions autonomously, not just answer questions, but use tools, navigate software, and complete multi-step tasks? These benchmarks test whether a model can operate like an assistant that does things, not just one that says things.
Key signal: Agentic tasks expose failure modes, getting stuck, losing context across steps, making unrecoverable errors, that simple question-answer don’t cover.
Long-Context & Document Understanding
These benchmarks test whether a model can retrieve, connect, and reason over information spread across very long inputs in a long document.
Key signal: A model may technically support a large context window but quietly degrade in quality the deeper into a document it needs to look.
Vision & Multimodal Reasoning
These benchmarks test whether a model can genuinely reason about visual content (e.g. charts, diagrams, photographs, scanned documents) alongside text.
Key signal: Parsing a document image and reasoning about a diagram are very different skills. A model strong at one is not necessarily strong at the other.
Human Preference & Instruction Following
Automated tests measure specific skills, but not whether a model is good at interacting with humans. Human preference benchmarks collect votes from real users on which response they prefer without knowing which model produced it.
Key signal: A model can score well on capability benchmarks while still feeling unhelpful or frustrating to use in practice.
Safety & Alignment
Safety benchmarks test bias ,toxicity, unsafe output generation, jail-break, resistance to manipulation, and whether a model can be tricked into producing harmful outputs.
Key signal: Capability and safety do not automatically go hand in hand. Some of the most capable models require the most careful safety evaluation.

Knowledge & Factual Reasoning
The most natural place to start evaluating a model is: does it know things? The first generation of knowledge benchmarks tested broad coverage. As models mastered those, the tests had to get deeper and more expert.
MMLU
MMLU (Massive Multitask Language Understanding) contains 16k+ multiple-choice questions covering 57 academic subjects like humanities (law, history, philosophy, etc.), social sciences (politics, geography, etc.), STEM (science, math, physics, etc), medicine, etc. GPT-3 model scored around 43.9% in 2020 compared to human expert’s 89.8% on MMLU. Today every frontier model exceeds 88%. A 2-point gap between models falls within measurement noise. MMLU is now a floor check, useful only for confirming a model isn’t broken.
# Example Question:
One of the reasons that the government discourages and regulates monopolies is that
(A) producer surplus is lost and consumer surplus is gained.
(B) monopoly prices ensure productive efficiency but cost society allocative efficiency.
(C) monopoly firms do not engage in significant research and development.
(D) consumer surplus is lost with higher prices and lower levels of output.
## Answer: DMMLU-Pro
MMLU-Pro is an upgrade over MMLU with 12k+ graduate-level reasoning-based questions with ten answer choices instead of four, making guessing much harder. As of early 2026, the leading score has already reached ~90%, and MMLU-Pro is itself approaching saturation.
# Example Question:
Ms. Chen purchased a used car, worth $1650, on the installment plan, paying $50 down and $1,840 in monthly installment payments over a period of two years. What annual interest rate did she pay?
Options:
A. 10% B. 17.5% C. 15.2% D. 13.3% E. 20% F. 19.8% G. 18% H. 16% I. 12% J. 14.4%
## Answer: JGPQA Diamond
Graduate-Level Google-Proof Q&A contains much complex questions. Its 198 questions in biology, physics, and chemistry were written by PhD-level domain experts and designed to be unsolvable by searching the web.
# Example Question:
Methylcyclopentadiene was allowed to react with methyl isoamyl ketone and a catalytic amount of pyrrolidine. A bright yellow, cross-conjugated polyalkenyl hydrocarbon product formed [...] How many chemically distinct isomers make up the final product (not counting stereoisomers)?
(a) 2 (b) 16 (c) 8 (d) 4
## Answer: b
Explanation Methylcyclopentadiene exists as an interconverting mixture
of 3 isomers [...] if there are 4 dienes, and 4 different directions of approach
the dienophile can take to each of them, there are 4*4 = 16 possible products- Skilled non-experts with unrestricted internet access: 34%
- PhD experts in the relevant field: ~65%
- GPT-5.4 (April 2026): 92%
- Claude Fable 5 and Gemini 3.1 Pro (June 2026): 94%
Frontier models have surpassed PhD experts on subject matter. Gemini 3.1 Pro (94.3%), Claude Fable 5 (94.1%), and Claude Opus 4.8 (93.6%) currently lead the leaderboard . GPQA Diamond is approaching saturation at the very top but still separates models in the 60–90% range.
Note that human expert scores vary across benchmarks: ~65% on GPQA Diamond (narrow, field-specific questions) versus ~90% on HLE (broader questions across many fields). Both use domain experts, but GPQA tests depth within a subfield while HLE tests breadth across disciplines.
Humanity’s Last Exam (HLE)
HLE is the current ceiling for knowledge evaluation. It comprises 2,500 questions created by domain experts across math, humanities, and natural sciences, all written from scratch, making it nearly impossible for a model to have “seen” the answers during training. The current status in 2026 looks like this:
| Model | Score (no tools) | Score (with tools) |
|---|---|---|
| Claude Fable 5 | 59.0% | 64.5% |
| Claude Opus 4.8 | 49.8% | 57.9% |
| GPT-5.5 | ~41.4% | — |
| Gemini 3 Pro Preview | 37.5% | — |
| GPT-5 Pro | 31.6% | — |
| DeepSeek-V4 | ~28% | — |
| Human domain experts (reference) | ~90% | — |
The “with tools” means models can run code or search the web during the test. That gap tells you how much a model depends on external tools versus internal reasoning. At the current pace, HLE may saturate within a year or two, following the same arc as every benchmark before it.
LiveBench
LiveBench takes a different approach to keeping knowledge benchmarks fresh: it releases new questions monthly, drawn from recent math competitions, research papers, etc. Because questions are always fresh, models cannot have memorized the answers during training. It contains 18 tasks in 6 categories: math, coding, reasoning, language, instruction following, and data analysis.
# Example Question:
There are 3 people standing in a line numbered 1 through 3 in a left to right order.
Each person has a set of attributes: Food, Nationality, Hobby.
The attributes have the following possible values:
- Food: nectarine, garlic, cucumber
- Nationality: chinese, japanese, thai
- Hobby: magic-tricks, filmmaking, puzzles
and exactly one person in the line has a given value for an attribute.
Given the following premises about the line of people:
- the person that likes garlic is on the far left
- the person who is thai is somewhere to the right of the person who likes magic-tricks
- the person who is chinese is somewhere between the person that likes cucumber and the person
who likes puzzles
Answer the following question: What is the hobby of the person who is thai? Return your
answer as a single word, in the following format: **X**, where X is the answer.Mathematics & Logical Reasoning
Mathematical reasoning tests the ability to chain together logical steps to solve math and logic questions.
GSM8K and HellaSwag
GSM8K tests grade-school math word problems. HellaSwag tests commonsense reasoning i.e. whether a model can pick the most sensible ending to a story. Both are now saturated with models scoring above 95% and 92% respectively. They are only useful as quick sanity checks to make sure a model isn’t broken.
# Example question from GSM8k:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
## Answer
Natalia sold 48/2 = <<48/2=24>>24 clips in May.
Natalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.
Answer: 72
# Example question from HellaSwag:
A bearded man is seen speaking to the camera and making several faces. the man
a) then switches off and shows himself via the washer and dryer rolling down a towel and scrubbing the floor. (0.0%)
b) then rubs and wipes down an individual’s face and leads into another man playing another person’s flute. (0.0%)
c) is then seen eating food on a ladder while still speaking. (0.0%)
d) then holds up a razor and begins shaving his face. (100.0%)AIME
AIME (American Invitational Mathematics Examination) consists of 15 difficult competition math problems with integer answers. It became a useful evaluation once the easier tests saturated. Top frontier models in 2026 approach ceiling performance on AIME 2025, thus pushing the field toward harder contests like the USAMO and PutnamBench.
FrontierMath
It consists of hundreds of unpublished challenging math problems. These are divided into 4 difficulty tiers with level 4 for research-level math.
# Example Question:
Construct a degree 19 polynomial p(x) ∈ C[x] such that X := {p(x) = p(y)} ⊂ P1 × P1 has at least 3 (but not all linear) irreducible components over C. Choose p(x) to be odd, monic, have real coefficients and linear coefficient -19 and calculate p(19).
## Answer: 1876572071974094803391179ARC-AGI-2
ARC-AGI-2 tests abstract reasoning and fluid intelligence, the ability to solve novel visual puzzles from just a few examples, with no relevant training data to draw on. The puzzles are grids of colored squares; the model must infer the underlying rule and complete the pattern. As of mid-2026, GPT-5.5 leads the leaderboard at ~85%, surpassing the average individual human performance of ~66%. Top human panel scores (where multiple experts must agree) still exceed the best AI, but the gap has closed dramatically since past year.
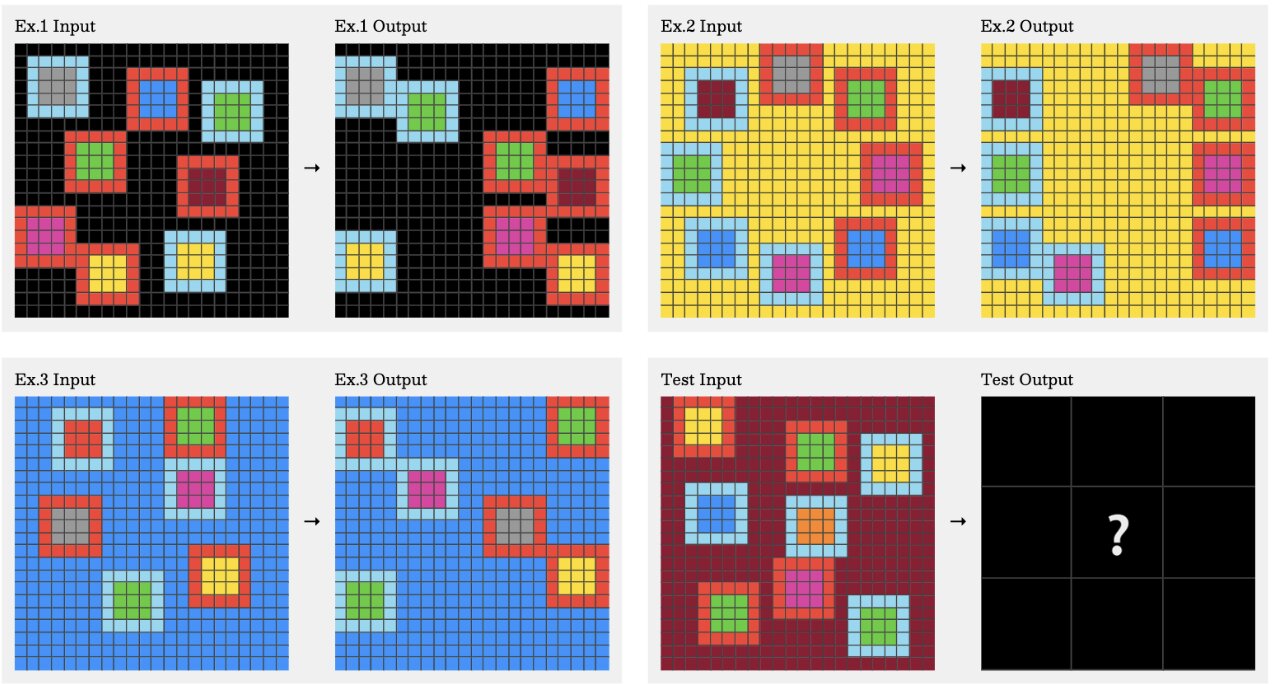
Coding & Software Engineering
These benchmarks measure whether a model can write, debug, and navigate real codebases, more than just producing plausible-looking code in isolation.
HumanEval
One of the first coding benchmarks, it asked models to complete Python functions from docstrings. It saturated above 93% and has been retired in favor of harder successors.
# Example Question
def words_string(s):
"""You will be given a string of words separated by
commas or spaces. Your task is to split the string
into words and return an array of the words.
For example:
words_string("Hi, my name is John") == ["Hi", "my",
"name", "is", "John"]
words_string("One, two, three, four, five, six") ==
["One", "two", "three", "four", "five", "six"]
"""SWE-Bench, SWE-Bench Verified, SWE-Bench Pro
The SWE-Bench measures: Given a real GitHub codebase and a bug report, can the model produce a correct patch? The SWE-Bench Verified is a subset of 500 problems from SWE-Bench verified by researchers. The SWE-Bench Pro is harder version with problems from spanning complex codebases e.g. consumer applications, B2B services, and developer tools. It contains 1865 problems from 41 actively managed repositories.
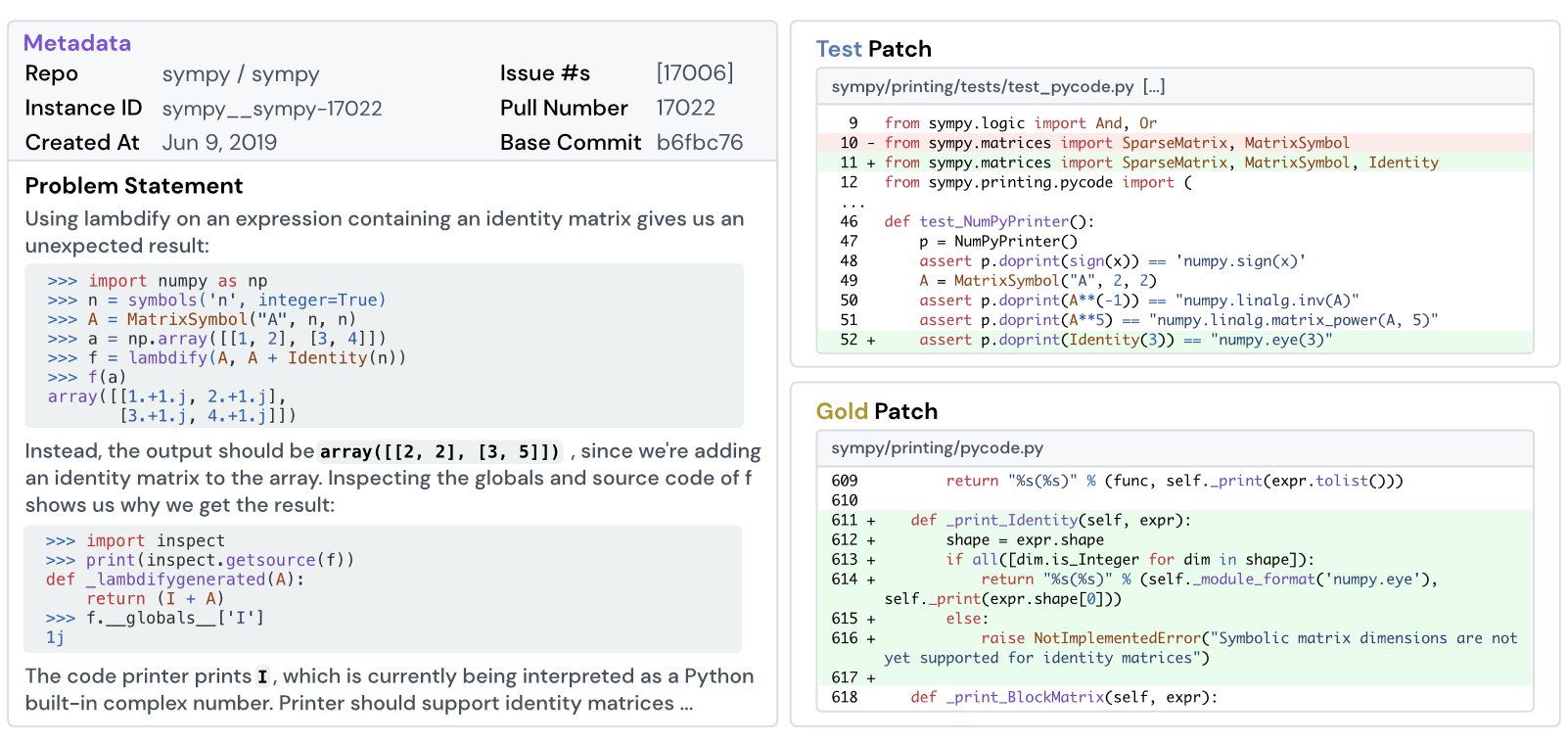
- 2023: 4.4% of issues solved
- 2024: 71.7% solved (+67 pp in one year)
- Mid-2026: Claude Fable 5 reached 80.3% on SWE-bench Pro
| Model | SWE-bench Verified | SWE-bench Pro |
|---|---|---|
| Claude Fable 5 | 95.0% | 80.3% |
| Claude Opus 4.8 | 88.6% | 69.2% |
| GPT-5.5 | 82.6% | 58.6% |
FrontierCode
FrontierCode (by Cognition) evaluates whether the model can write production-quality code that would eventually get merged by benchmarking it against PR rubrics. It measures correctness, test quality, scope discipline, style, and adherence to codebase standards. Claude Fable 5 scores 29.3% vs. Opus 4.8’s 13.4%, still wide open at research-grade engineering.
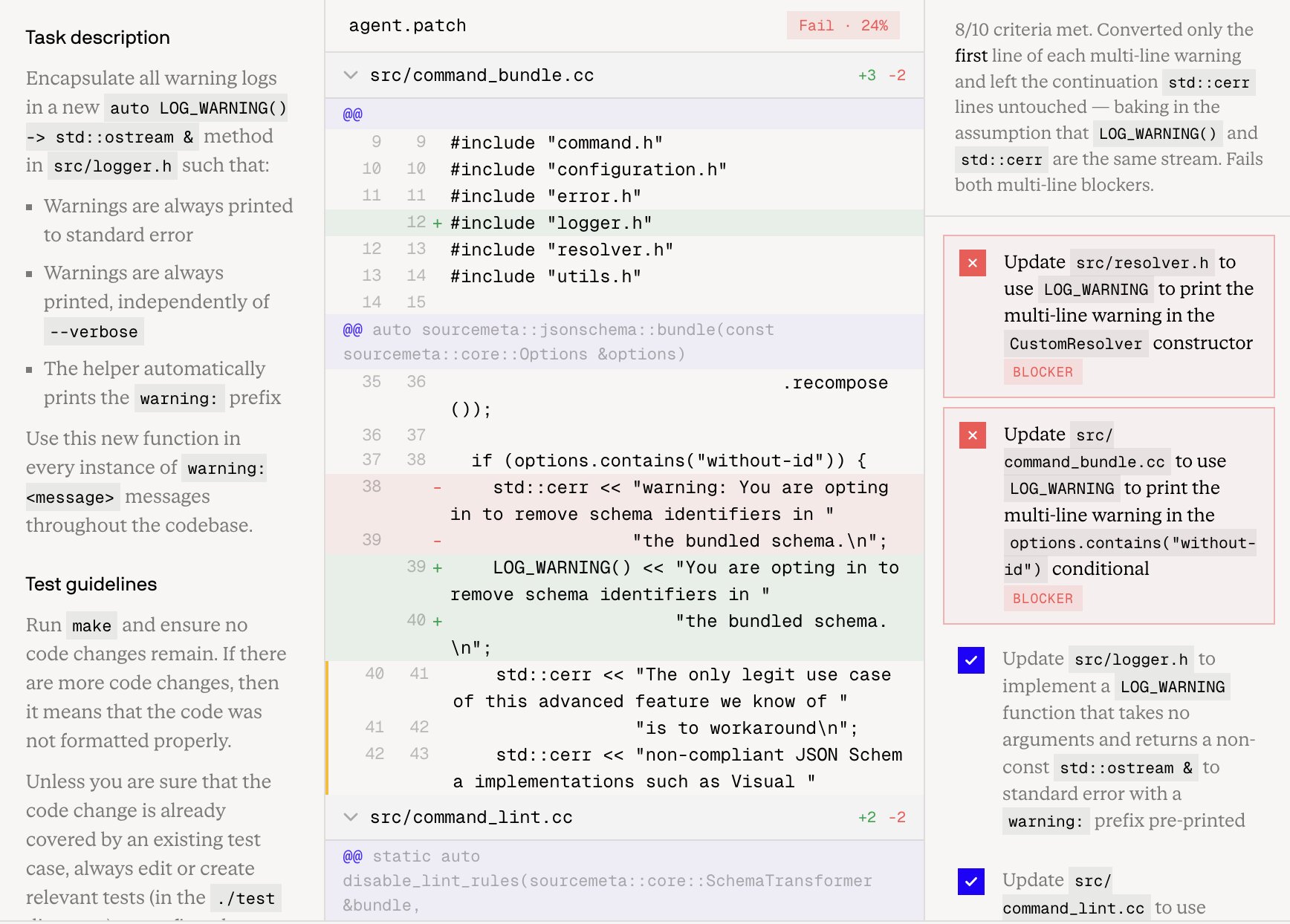
Agentic & Tool-Use Capability
Coding benchmarks test whether a model can produce the right output. Agentic benchmarks go further: can the model take actions across many steps, use tools, and recover when things go wrong? This is what it means to deploy a model as an autonomous assistant rather than a question-answering system.
Terminal-Bench 2.1
Terminal-Bench tests multi-step agentic terminal operation i.e. writing scripts, debugging shell pipelines, and interpreting command-line output across many turns. Instead of producing a single file, the model must operate an actual terminal environment end-to-end.
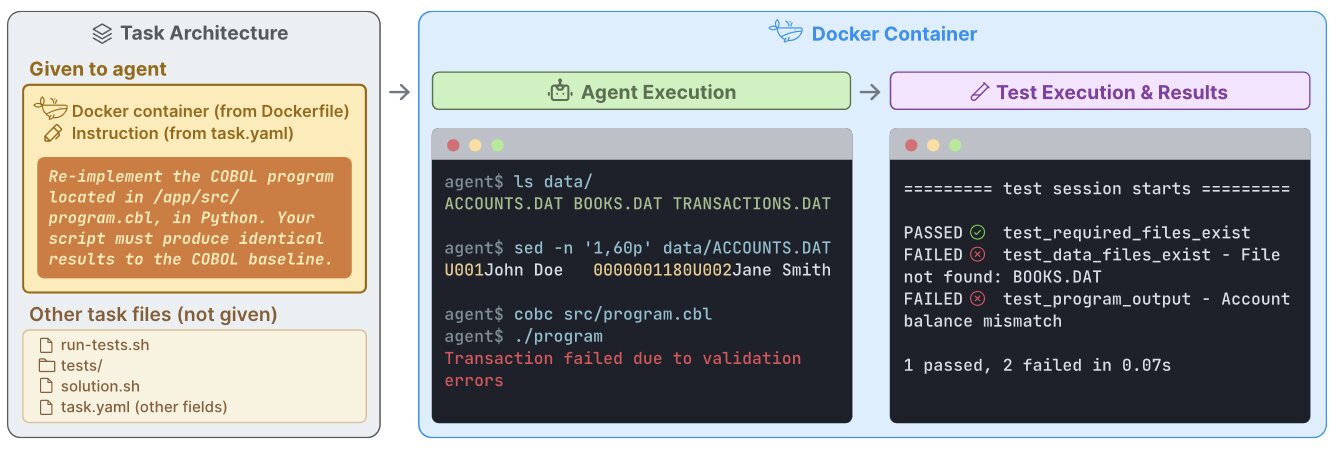
| Model | Terminal-Bench 2.1 |
|---|---|
| GPT-5.5 (Codex CLI) | 83.4% |
| Claude Fable 5 (Claude Code) | 83.1% |
| Claude Opus 4.8 (Claude Code) | 78.9% |
| Gemini 3.1 Pro | 70.7% |
OSWorld
OSWorld takes agentic evaluation the furthest: can a model operate a real computer? It tests tasks across operating systems: opening files, navigating a browser, running terminal commands, interacting with GUI applications. Unlike TerminalBench, OSWorld involves full visual interfaces and requires the model to perceive and act on a screen. Accuracy has risen from ~12% to 85.0% (Claude Fable 5). Human performance is around 72%, meaning models have now surpassed the human baseline on this benchmark.

Vision, Long-Context & Document Understanding
The benchmarks so far have mostly involved text. But real-world tasks often require more: understanding images, reasoning over long documents, or both at once. These two domains are closely related; both test what happens when you give a model richer, more complex input than a short text prompt.
Long-context benchmarks
They test whether models can actually use their large context windows. Context windows have grown from 4K tokens (GPT-3) to over 1M tokens (Gemini 3 Pro), but accepting a long document and reasoning over it are very different things. RULER and HELMET measure whether models can actually retrieve and connect information spread across very long inputs. A well-known failure mode here is “lost-in-the-middle” where a model handles the beginning and end of a document fine but loses track of content buried deeper inside.
Vision and multimodal reasoning
The models that handle both images and text are called vision-language models (VLMs). MMMU (Massive Multidisciplinary Multimodal Understanding) is the standard: college-level questions across six disciplines that require genuinely understanding images, not just reading captions. Top VLMs score in the 75–86% range, with room still to improve. More specific benchmarks test narrower skills:

| Benchmark | What it tests | 2026 SOTA | Status |
|---|---|---|---|
| MMMU | Multidisciplinary multimodal reasoning | ~86% | Active |
| MMT-Bench | Multimodal reasoning (broader) | ~78% | Active |
| ChartQA | Chart understanding | ~88% | Approaching ceiling |
| DocVQA | Document parsing | ~96% | Near-saturated |
| MMBench | Visual QA | ~85% | Active |
ChartQA and DocVQA are nearly saturated. MMMU and MMT-Bench still differentiate models, making them the active frontiers for multimodal evaluation.
Human Preference & Safety
All of the benchmarks above measure what a model can do. But two important questions remain: is it actually useful to interact with, and does it behave responsibly?
Human Preference
Chatbot Arena (LMArena) is the most widely trusted human preference evaluation. Users chat with two anonymous models simultaneously without knowing which is which, and vote on which response they prefer. Millions of these votes are aggregated into an Elo rating, the same system used in chess rankings. A higher Elo means a model wins more head-to-head matchups.
Arena Elo Ratings (June 2026):
| Model | Lab | Elo |
|---|---|---|
| Claude Fable 5 | Anthropic | 1,510 |
| Claude Opus 4.8 Thinking | Anthropic | 1,506 |
| GPT-5.5 High | OpenAI | 1,506 |
| Gemini 3.1 Pro | 1505 | |
| Grok 4.20 | xAI | 1496 |
| GLM-5.2 | Z.ai | 1488 |
| Qwen 3.7 Max | Alibaba | 1486 |
| DeepSeek-V4-Pro | DeepSeek | 1467 |
The top models are clustered within ~45 Elo points, the tightest spread on record. This has a practical implication: choosing a model now means matching it to your use case, not just picking the highest number. Price, latency, context window, and domain fit often matter more than raw capability differences.
The Open LLM Leaderboard v2 (HuggingFace) provides a consistent automated harness for comparing open-weight models across six benchmarks. Its value is standardization, any model can be run through the same evaluation pipeline.
Safety & Alignment
Safety evaluation is the least standardized part of the benchmark landscape, but it is growing in importance. StrongREJECT tests whether a model refuses harmful requests robustly. TruthfulQA evaluates whether models produce plausible-sounding falsehoods. HarmBench covers a broader range of harmful behaviors.
These benchmarks matter because capability and safety do not automatically improve together. A model that tops the coding leaderboard is not necessarily the most honest or the hardest to manipulate. As frontier models are deployed in higher-stakes settings, safety benchmarks will become as standard in model cards as GPQA Diamond or SWE-bench.
Domain-Specific Benchmarks
The benchmarks covered so far measure general capabilities i.e. how well a model reasons, codes, or understands images across a broad range of tasks. But in practice, many teams deploying AI care about a specific domain: will this model handle medical questions accurately? Can it reason about legal contracts? Does it understand financial statements?
Domain-specific benchmarks answer those questions. They tend to be narrower and harder to saturate, because they demand real subject-matter expertise rather than broad pattern-matching.
| Benchmark | Domain | What it tests |
|---|---|---|
| MedQA | Healthcare | Medical licensing exam questions (USMLE-style); tests clinical reasoning and medical knowledge |
| MedBench | Healthcare | Broader clinical tasks: diagnosis, treatment planning, patient communication |
| LegalBench | Law | 162 legal reasoning tasks covering contract analysis, statutory interpretation, case outcome prediction |
| FinanceBench | Finance | Questions over real financial documents: earnings reports, SEC filings, balance sheets |
| TaxEval | Tax & accounting | Tax preparation accuracy across common filing scenarios |
| SciCode | Scientific research | Code-driven scientific problem-solving across physics, chemistry, and biology |
A model that scores well on GPQA Diamond may still struggle on MedQA, because clinical reasoning requires not just broad science knowledge but familiarity with how medical decisions are framed. Similarly, high Arena Elo does not predict LegalBench performance; legal tasks require precision and citation accuracy that general helpfulness does not capture.
As frontier labs compete for enterprise use cases, domain-specific benchmarks are becoming a primary differentiator. Choosing a model for a specialized deployment increasingly means running it through the relevant domain benchmark, not just checking its MMLU or Arena Elo score.
Why Benchmarks Break Down
Running through each domain makes clear how much progress the field has made. But it also reveals a deeper problem: benchmarks have a shelf life, and that shelf life is shrinking.

Contamination
When a benchmark is public, its questions can appear in training data. Models that have “seen” the answers during training score higher than their genuine capability warrants. Invalid question rates from audits range from 2% (MMLU Math) to 42% (GSM8K). This is why the field increasingly favors benchmarks like HLE whose questions were never publicly available before release.
Saturation Churn
Every benchmark has a shelf life. MMLU lasted ~5 years. GPQA Diamond is approaching the end of its useful life after ~2 years. HLE may saturate within 1-2 years. The field runs a constant race to produce harder, cleaner evaluations before the current ones become useless.
Gaming
When labs know which benchmarks their models will be judged on, they optimize for those specific tests, intentionally or implicitly through training data choices. A model that scores well on a benchmark may not genuinely have the underlying capability the benchmark was designed to measure.
Static vs Dynamic Benchmarks
The response to these problems is a shift toward dynamic benchmarks like LiveBench (monthly refresh), MathArena (fresh olympiad problems), and HLE (never-before-published questions). These are harder to game and contaminate, but also harder to use for tracking progress over time.
Where the Frontier Stands (Mid-2026)
Putting it all together, here is the current state across the key benchmarks:
| Benchmark | Domain | Top Score | Leader | Status |
|---|---|---|---|---|
| MMLU | Knowledge breadth | 92.5% | Multiple | Saturated |
| MMLU-Pro | Graduate knowledge | 90% | Gemini 3 Pro Preview | Near-saturated |
| GPQA Diamond | PhD-level science | 94.3% | Gemini 3.1 Pro | Active, saturating |
| HLE | Knowledge frontier | 59.0% | Claude Fable 5 | Active, fast-improving |
| AIME 2025 | Competition math | 100% | Multiple | Saturated |
| FrontierMath | Research math | ~52% | GPT-5.5 Pro | Active |
| ARC-AGI-2 | Fluid reasoning | ~85% | GPT-5.5 | Active, fast-improving |
| SWE-bench Pro | Agentic coding | 80.3% | Claude Fable 5 | Active, saturating |
| TerminalBench 2.1 | Agentic terminal ops | 83.4% | GPT-5.5 (Codex CLI) | New, active |
| FrontierCode | Research-level coding | 29.3% | Claude Fable 5 | Wide-open |
| OSWorld | Agentic computer tasks | 85.0% | Claude Fable 5 | Active |
| Arena Elo | Human preference | ~1,510 | Claude Fable 5 | Converged |
No model leads across all benchmarks. ARC-AGI-2 remains genuinely wide open. The agentic benchmarks, TerminalBench and OSWorld, are where the most active competition is happening right now.
Conclusion
Benchmarking frontier AI models is a fast-changing field that requires regular updates. Tests saturate, harder ones replace them, and the cycle repeats faster each year. No single benchmark tells the full story, and no single model leads across all domains.
Choosing a model is less about finding the highest score and more about matching capability to use case, whether that’s knowledge reasoning, coding, agentic tasks, vision, or a specific domain like medicine or law.
And if history is any guide, the benchmarks you read about today will be obsolete within two years. The only constant is that the frontier keeps moving.
QUIZ: Test Your Benchmark Knowledge
References:
- Paper: MMLU, Measuring Massive Multitask Language Understanding (MMLU)
- Paper: MMLU-Pro, A More Robust and Challenging Multi-Task Language Understanding Benchmark
- Leaderboard: MMLU-Pro
- Paper: GPQA, A Graduate-Level Google-Proof Q&A Benchmark
- Leaderboard: GPQA Diamond
- Paper: Humanity’s Last Exam
- Leaderboard: Humanity’s Last Exam
- Paper: LiveBench, A Challenging, Contamination-Free LLM Benchmark
- Paper: GSM8K, Training Verifiers to Solve Math Word Problems
- Website: HellaSwag
- Paper: FrontierMath, A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
- Paper: ARC-AGI-2
- Leaderboard: ARC-AGI-2
- Paper: HumanEval, Evaluating Large Language Models Trained on Code
- Paper: SWE-Bench, Can Language Models Resolve Real-World GitHub Issues?
- Leaderboard: SWE-Bench Verified vals.ai
- Leaderboard: SWE-Bench Pro
- Blog: FrontierCode
- Paper: OSWorld, Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
- Paper: MMMU, A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark
- Paper: Chatbot Arena, An Open Platform for Evaluating LLMs by Human Preference
- Leaderboard: Chatbot Arena
- Paper: Terminal-Bench
- Leaderboard: Terminal-Bench 2.1
- Paper: TruthfulQA, Measuring How Models Mimic Human Falsehoods
- Paper: A StrongREJECT for Empty Jailbreaks
- Paper: MedQA, What Disease does this Patient Have?
- Paper: LegalBench, A Collaboratively Built Benchmark for Measuring Legal Reasoning in LLMs
- Paper: FinanceBench, A New Benchmark for Financial Question Answering
- Blog: Claude Fable 5 and Claude Mythos 5
- Blog: reviewing GPT‑5.6 Sol: a next-generation model


Comments