Jekyll2024-06-17T02:41:59+00:00https://kharshit.github.io/feed.xmlHarshit KumarHarshit Kumar - personal website and blogMatrix Multiplication in CUDA2024-06-07T00:00:00+00:002024-06-07T00:00:00+00:00https://kharshit.github.io/blog/2024/06/07/matrix-multiplication-cudaMatrix multiplication is at the heart of deep learning. In this evolving world of LLMs, the need for fast and efficient matrix multiplications is paramount. Nvidia CUDA allows you to perform matrix operations on GPU in a faster way.
CUDA (Compute Unified Device Architecture) is a parallel computing platform and application programming interface (API) model. CUDA programming model provides an abstraction of GPU architecture (API for GPUs).
In this blog post, we will explore how to implement matrix multiplication using CUDA. We will start with a naive implementation on the CPU and then demonstrate how to significantly speed up the process using CUDA.
Naive C++ Implementation on CPU
Since in most hardwares, matrices are stored in row-major format, let’s define our 2d matrices as row-major 1d arrays.
structMatrix{intheight;intwidth;float*elements;// height x width// you can also use std::vector<float> elements for automatic memory management};
Matrix multiplication for computing each element of matrix C from matrices A and B can be written as follows:
We can use the below main() function to call our matMulCPU() and measure its performance.
// Function to initialize a matrix with random valuesvoidinitializeMatrix(Matrix&mat){for(inti=0;i<mat.height*mat.width;++i)mat.elements[i]=static_cast<float>(rand()%100);}intmain(){intM=1024;// Rows of A and CintK=768;// Columns of A and rows of BintN=1024;// Columns of B and C // Allocate matrices A, B, and CMatrixA={M,K,newfloat[M*K]};// 1024x768MatrixB={K,N,newfloat[K*N]};// 768x1024 MatrixC={M,N,newfloat[M*N]};// 1024x1024// Initialize matrices A and B with random valuesinitializeMatrix(A);initializeMatrix(B);// Measure the time taken for matrix multiplication on the CPUautostart=std::chrono::high_resolution_clock::now();matMulCPU(A,B,C);autostop=std::chrono::high_resolution_clock::now();std::chrono::duration<float>duration=stop-start;cout<<"CPU matrix multiplication time: "<<duration.count()*1000.0f<<" ms"<<endl;// Clean up memorydelete[]A.elements;delete[]B.elements;delete[]C.elements;return0;}
Naive CUDA Kernel
In CUDA, we define a CUDA kernel, which is a function (e.g. C++ function) executed by CUDA.
In CUDA programming model, there is a three-level hierarchy. The threads are the smallest unit of execution. These threads are grouped into a CUDA thread block. CUDA blocks are grouped into arrays called grids. The kernel is written from the perspective of a single thread in CUDA. Thus, a kernel is executed as a grid of blocks of threads.
CUDA grid of thread blocks (source: Nvidia CUDA docs)
On a CPU, matrix multiplication is typically performed sequentially, where each element of the output matrix is computed one after another. This process can be slow for large matrices due to the limited number of CPU cores available for parallel execution. In contrast, the GPU excels at parallel processing. A CUDA kernel is executed by many threads running simultaneously, allowing for significant speedup in computations like matrix multiplication. The GPU’s architecture enables it to handle thousands of threads concurrently, making it well-suited for tasks with high levels of parallelism.
Let’s re-write the above matrix multiplication code in CUDA. We use __global__ keyword to define a CUDA kernel. Here, we assign a thread for calculation of each element of output matrix C. And, multiple such threads are run in parallel. Each thread reads one row of A and one column of B to compute one element of C.
Threads and blocks are indexed using the built-in 3D variable threadIdx and blockIdx. The blockDim gives the dimension of thread block. We can access index using dot attribute e.g. threadIdx.x, threadIdx.y, and threadIdx.z. Thus, for 2d thread block, we can access particular element of C using a combination of these as shown in below code.
__global__voidmatMulNaiveKernel(MatrixA,MatrixB,MatrixC){introw=blockIdx.y*blockDim.y+threadIdx.y;intcol=blockIdx.x*blockDim.x+threadIdx.x;// Each thread accumulates one element of C by accumulating results into cValuefloatcValue=0;// C[i][j] = sum_k A[i][k] * B[k][j]// Iterates over common dimensions of A and B (k = A.width = B.height)if(row<A.height&&col<B.width){for(intk=0;k<A.width;++k)cValue+=A.elements[row*A.width+k]*B.elements[k*B.width+col];C.elements[row*C.width+col]=cValue;}}
We create a 16x16 thread block (256 threads with 16 each in x and y-direction). We define (B.width/BLOCK_SIZE, A.height/BLOCK_SIZE) blocks per grid. Extra operations below is to take care of the last tile if size isn’t perfectly divisible.
This setup ensures that the CUDA kernel efficiently processes the entire matrix by dividing the workload among the available threads and blocks.
To execute CUDA program:
Copy the input data from host (cpu) memory to device (gpu) memory. This is called host-to-device (H2D) transfer.
Run CUDA kernel on data.
Copy the results from device memory to host memory, also called device-to-host (D2H) transfer.
We pass our kernel to the runKernel() function that also takes CPU matrices A and B. It copies the data from CPU to GPU, runs kernel, copy result from GPU to CPU, and return the result matrix C.
voidrunKernel(void(*kernel)(Matrix,Matrix,Matrix),constMatrix&A,constMatrix&B,Matrix&C,dim3gridDim,dim3blockDim){// Load matrices to device memoryMatrixd_A,d_B,d_C;size_tsize_A=A.width*A.height*sizeof(float);size_tsize_B=B.width*B.height*sizeof(float);size_tsize_C=C.width*C.height*sizeof(float);d_A.width=A.width;d_A.height=A.height;d_B.width=B.width;d_B.height=B.height;d_C.width=C.width;d_C.height=C.height;// Allocate device memoryCUDA_CHECK_ERROR(cudaMalloc(&d_A.elements,size_A));CUDA_CHECK_ERROR(cudaMalloc(&d_B.elements,size_B));CUDA_CHECK_ERROR(cudaMalloc(&d_C.elements,size_C));// Copy A, B to device memoryCUDA_CHECK_ERROR(cudaMemcpy(d_A.elements,A.elements,size_A,cudaMemcpyHostToDevice));CUDA_CHECK_ERROR(cudaMemcpy(d_B.elements,B.elements,size_B,cudaMemcpyHostToDevice));autostart=std::chrono::high_resolution_clock::now();// Launch kernelkernel<<<gridDim,blockDim>>>(d_A,d_B,d_C);// Synchronize device memoryCUDA_CHECK_ERROR(cudaDeviceSynchronize());autoend=std::chrono::high_resolution_clock::now();std::chrono::duration<float>duration=end-start;std::cout<<"Kernel execution time: "<<duration.count()*1000.0f<<" ms"<<std::endl;// Copy C from device memory to host memoryCUDA_CHECK_ERROR(cudaMemcpy(C.elements,d_C.elements,size_C,cudaMemcpyDeviceToHost));// Free device memoryCUDA_CHECK_ERROR(cudaFree(d_A.elements));CUDA_CHECK_ERROR(cudaFree(d_B.elements));CUDA_CHECK_ERROR(cudaFree(d_C.elements));}
And, we call runKernel() function in above defined main() function.
CUDA Shared Memory Kernel
The previous CUDA kernel uses DRAM, but we can optimize performance by leveraging the GPU’s shared memory. Shared memory is faster but has limited capacity, so we cannot load entire matrices at once. Instead, we divide the matrices into smaller sub-matrices, or tiles, that fit into shared memory.
Shared memory matmul (source: Nvidia CUDA docs)
Shared memory is allocated per thread block, allowing threads within the same block to communicate efficiently. Each thread block is responsible for computing one square sub-matrix \(C_{sub}\) of C by loading tiles of input matrices A and B from global memory to shared memory. Each thread within the block computes a single element of \(C_{sub}\) by iterating over the corresponding elements in the shared memory tiles, accumulating the results of the products. Finally, each thread writes its computed value to the appropriate position in global memory.
#define TILE_SIZE 16
// Kernel for matrix multiplication using tiling and shared memory__global__voidmatMulSharedMemoryKernel(MatrixA,MatrixB,MatrixC){// Shared memory for tiles of A and B__shared__floatshared_A[TILE_SIZE][TILE_SIZE];__shared__floatshared_B[TILE_SIZE][TILE_SIZE];// Calculate the global row and column index of the elementintglobalRow=blockIdx.y*blockDim.y+threadIdx.y;intglobalCol=blockIdx.x*blockDim.x+threadIdx.x;floatCvalue=0.0f;// Thread row and column within Csubintrow=threadIdx.y;intcol=threadIdx.x;// Loop over the tiles of the input matrices// A.width/TILE_SIZE and B.height/TILE_SIZE; take care of the last tilefor(intm=0;m<(A.width+TILE_SIZE-1)/TILE_SIZE;++m){// Load elements of A into shared memory// if shared memory defined using 1d array, we'd have used shared_A[row * TILE_SIZE + col]if(row<A.height&&(m*TILE_SIZE+col)<A.width){shared_A[row][col]=A.elements[globalRow*A.width+m*TILE_SIZE+col];}else{// When matrix dimensions are not exact multiples of the tile size,// some threads in the last blocks might access elements outside// the matrix boundaries. By setting out-of-bounds elements to zero,// we ensure that these threads do not contribute invalid values to final result.// e.g. Matrix A = [100x100] and TILE_SIZE = 16shared_A[row][col]=0.0f;}// Load elements of B into shared memoryif(col<B.width&&(m*TILE_SIZE+row)<B.height){shared_B[row][col]=B.elements[(m*TILE_SIZE+row)*B.width+globalCol];}else{shared_B[row][col]=0.0f;}// Synchronize to ensure all threads have loaded their elements__syncthreads();// Compute the partial resultfor(intk=0;k<TILE_SIZE;++k)Cvalue+=shared_A[row][k]*shared_B[k][col];// Synchronize to ensure all threads have completed the computation__syncthreads();}// Write the result to global memoryif(globalRow<C.height&&globalCol<C.width)C.elements[globalRow*C.width+globalCol]=Cvalue;}
There are other ways to optimize the CUDA matrix multplication kernel further, such as:
Using Register Blocking: This technique involves utilizing the register file to hold smaller sub-blocks of the matrices, reducing the number of accesses to shared memory.
Loop Unrolling: By unrolling loops, you can decrease the overhead of loop control instructions and increase the efficiency of the computation.
Occupancy Optimization: Tuning the number of threads per block and the size of the blocks to achieve the highest possible occupancy on the GPU.
Prefetching: Loading data into shared memory or registers ahead of time to hide memory latency.
Asynchronous Memory Operations: Using CUDA streams and cudaMemcpyAsync to overlap computation and data transfer, further reducing idle times.
Low Precision: Using half-precision (FP16) or mixed-precision (FP16/FP32) arithmetic can improve performance on supported GPUs.
By combining these advanced optimization techniques with shared memory, you can achieve even greater performance gains for matrix multiplication on CUDA-enabled GPUs.
]]>Retrieval Augmented Generation (RAG) Chatbot for 10Q Financial Reports2024-04-26T00:00:00+00:002024-04-26T00:00:00+00:00https://kharshit.github.io/blog/2024/04/26/rag-financial-reports-llmWhile Large Language Models (LLMs) are revolutionary, they sometimes get it wrong—like citing varying figures for something as critical as Tesla’s total assets on a given date. In the accompanying figure, you can see ChatGPT4 giving different results when asked the same question multiple times. This problem is called LLM hallucinations. And that’s where Retrival Augmented Generation (RAG) comes in. In this blog post, I’ll describe how to create a Chabot for 10Q Financial Reports that leverages RAG.
LLM hallucination
What is Retrival Augmented Generation (RAG)?
It’s a framework that combines the strengths of information retrieval and generative language modeling to enhance the capabilities of machine learning systems, particularly in tasks that involve natural language understanding and generation. It involves two main components.
Retrieval Component: responsible for accessing an external knowledge source, such as a database or a document collection, to retrieve relevant information based on the input query.
Generation Component: leverages LLMs to generate response based on the context provided by the retrieval component.
Building RAG Chatbot
Dataset
The dataset primarily consists of financial documents, specifically 10-Q and 10-K filings from major publicly traded companies, such as Tesla, NVIDIA, and Apple. These documents are obtained from the U.S. Securities and Exchange Commission’s (SEC) EDGAR database, which is a reliable source for such financial reports. Each 10-Q and 10-K filing within the dataset contains a comprehensive overview of a company’s financial performance.
Tesla 10Q
Steps
We need to following the following steps to build a RAG Chatbot.
Problem statement: Given a PDF document and a query, retrieve the relevant details and information from the document as per the query, and synthesize this information to generate accurate answers.
Data Ingestion and Processing: Reading PDFs of financial reports and split the documents for efficient text chunking of long documents.
Retrieval-Augmented Generation (RAG): Combination of document retrieval with the generative capabilities of the chosen language models.
Large Language Models: Evaluation of various models, including GPT-3.5-turbo, LLama 2, Gemma 1.1, etc.
Conversation Chain and Prompt Design: Crafting of a prompt template designed for concise two-sentence financial summaries.
User interface: Designing Chatbot like user interface.
First, we load the 10-Q PDF using PyPDFLoader.
fromlangchain.document_loadersimportPyPDFLoader# create a loader
loader=PyPDFLoader(r"data/tsla-20230930.pdf")
We then split data in chunks using a recursive character text splitter to handle large documents.
We now create the embeddings using Sentence Transformer and HuggingFace embeddings. In order to create vector embeddings, we use the open-source Chroma vector database.
We use HuggingFace to load LLama 2 model and create a HuggingFace pipeline. Since, we’re going to use LangChain, we use HugggingFacePipeline wrapper from LangChain to create LangChain llm object, which we’re going to use to do further processing.
If we want to use GPT models from OpenAI, we can diretly use openai API.
importosimportopenaifromlangchain.chat_modelsimportChatOpenAI# Set your OpenAI API key
openai.api_key=os.getenv("OPENAI_API_KEY")# Define LLM
llm=ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0)
Finally, we create a LangChain chain for our RAG system. We also pass a task-specific prompt to guide LLM for question answering wrt RAG for financial reports.
fromlangchain.promptsimportChatPromptTemplatefromlangchain.schema.runnableimportRunnablePassthroughfromlangchain.schema.output_parserimportStrOutputParser# Define prompt template
template="""You are an assistant for question-answering tasks for Retrieval Augmented Generation system for the financial reports such as 10Q and 10K.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use two sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""prompt=ChatPromptTemplate.from_template(template)retriever=vectordb.as_retriever()# Setup RAG pipeline
conversation_chain=({"context":retriever,"question":RunnablePassthrough()}|prompt|llm|StrOutputParser())
Finally, we invoke our conversation chain on user input.
user_input="What's the total assets of Tesla?"output=conversation_chain.invoke(user_input)
We can integrate our code with some frontend e.g. with Dash to have chatbot like interface.
PyTorch and Tensorflow 2 (by default) uses immediate (eager) mode. It follows the “define by run” principle i.e. you can execute the code as you define it. Consider the below simple example in Python.
a=3b=4c=(a**2+b**2)**0.5c# 5.0
Tensorflow 1.0, on the other hand, uses deferred execution i.e. you define a series of operation first, then execute – most exceptions are be raised when the function is called, not when it’s defined. In the example below, a and b are placeholders, and the equation isn’t executed instantly to get the value of p unlike in immediate execution example above.
In static graph (left side), the neuron gets compiled into a symbolic graph in which each node represents individual operations, using placeholders for inputs and outputs. Then the graph is evaluated numerically when numbers are plugged into the placeholders.
Dynamic graphs (righ side) can change during successive forward passes. Different nodes can be invoked according to conditions on the outputs of the preceding nodes, for example, without a need for such conditions to be represented in the graph.
Source: Deep Learning with PyTorch book
Installation
I recommend creating a conda environment first. Then, follow the steps on PyTorch Getting Started. By default, the PyTorch library contains CUDA code, however, if you’re using CPU, you can download a smaller version of it.
You can use collect_env.py script to test the installation.
Note: This tutorial works fine on PyTorch 1.4, torchvision 0.5.
Tensors
You can create and train neural networks in numpy as well. However, you won’t be able to use GPU, and will have to write the backward pass of gradient descent yourself, write your layers etc. The deep learning libraries, like PyTorch, solves all these types of problems. In short,
PyTorch = numpy with GPU + DL stuff
Note that in order to maintain reproducibility, you need to set both numpy and pytorch seeds.
importnumpyasnpimporttorchprint(torch.__version__)# reproducibility: https://pytorch.org/docs/stable/notes/randomness.html
np.random.seed(0)torch.manual_seed(7)# when using CUDA and running on the CuDNN backend
torch.cuda.manual_seed_all(0)torch.backends.cudnn.deterministic=Truetorch.backends.cudnn.benchmark=False
1.4.0
A tensor is a generalization of matrices having a single datatype: a vector (1D tensor), a matrix (2D tensor), an array with three indices (3D tensor e.g. RGB color images). In PyTorch, similar to numpy, every tensor has a data type and can reside either on CPU or on GPU. For example, a tensor having 32-bit floating point numbers has data type of torch.float32 (torch.float). If the tensor is on CPU, it’ll be a torch.FloatTensor, and if on gpu, it’ll be a torch.cuda.FloatTensor. You can perform operations on these tensors similar to numpy arrays. In fact, PyTorch even has same naming conventions for basic functions as in numpy.
# uninitialized tensor
print(torch.empty(2,2,dtype=torch.bool))# initialized tensor
# torch.zeros(2, 2)
# torch.ones(2, 2)
print(torch.rand(2,2))# from a uniform distribution
print(torch.randn(2,2))# from standard normal distribution
The in-place operations in PyTorch are those that directly modify the tensor content in-place i.e. without creating a new copy. The functions that have _ after their names are in-place e.g. add_() is in-place, while add() isn’t. Note that certain python operations such as a += b are also in-place.
a=torch.tensor([[1,1],[1,1]])b=torch.tensor([[1,1],[1,1]])# c = a + b # normal operation
b.add_(a)# in-place operation
print(b)
# check if CUDA available
print(torch.cuda.is_available())# check if tensor on GPU
print(b.is_cuda)# move tensor to GPU
print(b.cuda())# defaults to gpu:0 # or to.device('cuda')
# move tensor to CPU
print(b.cpu())# or to.device('cpu')
# check tensor device
print(b.device)
If you’ve multiple GPUs, you can specify it using to.device('cuda:<n>). Here, n (0, 1, 2, …) denotes GPU number.
Autograd
automatic differentiation: calculate the gradients of the parameters (W, b) with respect to the loss, L
It does so by keeping track of operations performed on tensors, then going backwards through those operations, calculating gradients along the way. For this, you need to set requires_grad = True on a tensor.
Source: Deep Learning with PyTorch book
Consider the function z whose derivative w.r.t. x is x/2.
x=torch.randn(2,2,requires_grad=True)y=x**2# y.retain_grad() # retain gradient
# each tensor has a .grad_fn attribute that references a Function that created it
print(f'y.grad_fn: {y.grad_fn}')z=y.mean()print(f'x.grad: {x.grad}')z.backward()print(f'x.grad: {x.grad}\n\
x/2: {x/2}\n\
y.grad: {y.grad}')# dz/dy
Note that the derivative of z w.r.t. y is None since gradients are calculated only for leaf variables by default.
You could use retain_grad() to calculate the gradient of non-left variables. You can use retain_graph=True so that the buffers are not freed. To reduce memory usage, during the .backward() call, all the intermediary results are deleted when they are not needed anymore. Hence if you try to call .backward() again, the intermediary results don’t exist and the backward pass cannot be performed.
z.backward()
---------------------------------------------------------------------------RuntimeErrorTraceback(mostrecentcalllast)<ipython-input-9-40c0c9b0bbab>in<module>()---->1z.backward()/usr/local/lib/python3.6/dist-packages/torch/tensor.pyinbackward(self,gradient,retain_graph,create_graph)193products.Defaultsto``False``.194"""
--> 195 torch.autograd.backward(self, gradient, retain_graph, create_graph)
196
197 def register_hook(self, hook):
/usr/local/lib/python3.6/dist-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)
97 Variable._execution_engine.run_backward(
98 tensors, grad_tensors, retain_graph, create_graph,
---> 99 allow_unreachable=True) # allow_unreachable flag
100
101
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
Note: Calling .backward() only works on scalar variables. When called on vector variables, an additional ‘gradient’ argument is required. In fact, y.backward() is equivalent to y.backward(torch.tensor(1.)). torch.autograd is an engine for computing vector-Jacobian product. Read more.
To stop a tensor from tracking history, you can call .detach() to detach it from the computation history, and to prevent future computation from being tracked OR use with torch.no_grad(): context manager.
print(x.requires_grad)print((x**2).requires_grad)withtorch.no_grad():print((x**2).requires_grad)print(x.requires_grad)y=x.detach()# best way to copy a tensor
# y = x.detach().clone()
print(y.requires_grad)
TrueTrueFalseTrueFalse
Now, we’re going to train a simple dog classifier.
Data loading and augmentation
Dataset class is an abstract class representing a dataset.
Custom Dataset: It must inherit from Dataset class and override the __len__ so that len(dataset) returns the size of the dataset and __getitem__ to support the indexing such that dataset[i] can be used to get ith sample.
In this tutorial, we’re going to use ImageFolder.
The DataLoader takes a dataset (such as you would get from ImageFolder) and returns batches of images and the corresponding labels.
We’re also going to normalize our input data and apply data augmentation techniques. Note that we don’t apply data augmentation to validation and testing split.
For nomalization, the mean and standard deviation should be taken from the training dataset, however, in this case, we’re going to use ImageNet’s statistics (why?).
There are two ways we can implement different layers and functions in PyTorch. torch.nn module (python class) is a real layer which can be added or connected to other layers or network models. However, torch.nn.functional (python function) contains functions that do some operations, not the layers which have learnable parameters such as weights and bias terms. Still, the choice of using torch.nn or torch.nn.functional is yours. torch.nn is more convenient for methods which have learnable parameters. It keep the network clean.
Note: Always use nn.Dropout(), not F.dropout(). Dropout is supposed to be used only in training mode, not in evaluation mode, nn.Dropout() takes care of that.
The spatial dimensions of a convolutional layer can be calculated as: (W_in−F+2P)/S+1, where W_in is input, F is filter size, P is padding, S is stride.
classNet(nn.Module):def__init__(self):super(Net,self).__init__()# input image: (3, 224, 224)
self.conv1=nn.Conv2d(in_channels=3,out_channels=16,kernel_size=3,padding=1)# (16, 224, 224) --> (16, 112, 112) (halved by max-pool)
self.conv2=nn.Conv2d(16,32,3,padding=1)# (32, 56, 56)
self.conv3=nn.Conv2d(32,64,3,padding=1)self.pool=nn.MaxPool2d(2,2)# (64, 28, 28)
self.fc1=nn.Linear(64*28*28,512)self.fc2=nn.Linear(512,256)# no of classes `n_classes`: 133
self.fc3=nn.Linear(256,n_classes)self.dropout=nn.Dropout(0.25)defforward(self,x):## forward pass
x=self.pool(F.relu(self.conv1(x)))x=self.pool(F.relu(self.conv2(x)))x=self.pool(F.relu(self.conv3(x)))# flatten image input
x=x.view(-1,64*28*28)x=self.dropout(x)x=F.relu(self.fc1(x))x=self.dropout(x)x=F.relu(self.fc2(x))x=self.fc3(x)returnx# instantiate the CNN
model_scratch=Net()# move tensors to GPU if CUDA is available
model_scratch=model_scratch.to(device)print(model_scratch)
The classifier part of the model is a single fully-connected layer (fc): Linear(in_features=2048, out_features=1000, bias=True). This layer was trained on the ImageNet dataset, so it won’t work for our specific problem, so we need to replace the classifier.
# Freeze parameters so we don't backprop through them
forparaminmodel_transfer.parameters():param.requires_grad=Falsenum_ftrs=2048#model_transfer.fc.in_features # it's 2048, check fc layer of resnet
# creating model using Sequential API
classifier=nn.Sequential(nn.Linear(num_ftrs,512),nn.ReLU(),nn.Dropout(0.2),nn.Linear(512,133))model_transfer.fc=classifiermodel_transfer=model_transfer.to(device)print(model_transfer)summary(model_transfer,input_size=(3,224,224))
Training, Validation, and Inference
Since, it’s a classification problem, we’ll use cross-entropy loss function.
where, \(y_{i,j}\) denotes the true value i.e. 1 if sample i belongs to class j and 0 otherwise, and \(p_{i,j}\) denotes the probability predicted by your model of sample i belonging to class j.
nn.CrossEntropyLoss() combines nn.LogSoftmax() (log(softmax(x))) and nn.NLLLoss() (negative log likelihood loss) in one single class. Therefore, the output from the network that is passed into nn.CrossEntropyLoss needs to be the raw output of the network (called logits), not the output of the softmax function.
It is convenient to build the model with a log-softmax output using nn.LogSoftmax (or F.log_softmax) since the actual probabilities can be accessed by taking the exponential torch.exp(output), then negative log likelihood loss, nn.NLLLoss can be used. Read more.
criterion=nn.CrossEntropyLoss()# LogSoftmax + NLLLoss
# only train the classifier (fully-connected layers') parameters
optimizer=optim.Adam(model_transfer.fc.parameters(),lr=0.001)
one epoch = one forward pass and one backward pass of all the training examples.
batch size = the number of training examples in one forward/backward pass. The higher the batch size, the more memory space you’ll need.
number of iterations = number of passes, each pass using [batch size] number of examples. To be clear, one pass = one forward pass + one backward pass (we do not count the forward pass and backward pass as two different passes).
Example: if you have 1000 training examples, and your batch size is 4, then it will take 250 iterations to complete 1 epoch.
Note: the weights are updated after each batch, not epoch or iteration.
Calling backward leads derivatives to accumulate at leaf nodes. You need to zero the gradient explicitly after using it for parameter updates i.e. optimizer.zero_grad(). We can utilize this functionality to Increase effective batch size using gradient accmulation
deftrain(n_epochs,loaders,model,optimizer,criterion,use_cuda,save_path):"""returns trained model"""# initialize tracker for minimum validation loss
valid_loss_min=np.Infforepochinrange(1,n_epochs+1):# initialize variables to monitor training and validation loss
train_loss=0.0valid_loss=0.0###################
# train the model #
###################
model.train()forbatch_idx,(data,target)inenumerate(loaders['train']):# move to GPU, if available
# image, label
ifuse_cuda:data,target=data.cuda(),target.cuda()# .to(device)
# zero the parameter gradients
optimizer.zero_grad()# forward pass: compute predicted outputs by passing inputs to the model
# [N, C, H, W] -> [32, 3, 224, 224]
outputs=model(data)# calculate the loss
loss=criterion(outputs,target)# backward pass
loss.backward()# optimization step (update the weights)
optimizer.step()# record the average training loss
# train_loss += loss.item()*data.size(0)
# if using above method then divide loss "outside this for-loop":
# using this (to get epoch loss): train_loss = train_loss/len(loaders['train'])
train_loss+=((1/(batch_idx+1))*(loss.data-train_loss))######################
# validate the model #
######################
# set model to evaluation model (disables dropout etc)
model.eval()forbatch_idx,(data,target)inenumerate(loaders['valid']):ifuse_cuda:data,target=data.cuda(),target.cuda()# Turn off gradients for validation, saves memory and computations
withtorch.no_grad():outputs=model(data)loss=criterion(outputs,target)valid_loss+=((1/(batch_idx+1))*(loss.data-valid_loss))# print training/validation statistics
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(epoch,train_loss,valid_loss))## serialization: save the model if validation loss has decreased
ifvalid_loss<=valid_loss_min:print(f'Validation loss decreased ({valid_loss_min:.3f} --> {valid_loss:.3f}). Saving model ...')torch.save(model.state_dict(),save_path)valid_loss_min=valid_lossreturnmodel
The .parameters() only gives the module parameters i.e. weights and biases, while state_dict returns a dictionary containing a whole state of the module.
torch.nn only supports mini-batches. For example, nn.Conv2d will take in a 4D Tensor of NCHW (nSamples x nChannels x Height x Width) .If you have a single sample, just use input.unsqueeze(0) to add a fake batch dimension.
ONNX (Open Neural Network Exchange) is an open format to represent models thus allowing interoperability.
It defines a common set of operators (opsets) that a model uses and creates .onnx model file that can be converted to various frameworks.
device=torch.device("cuda:0"iftorch.cuda.is_available()else"cpu")print('Using',device)batch_size=1# just take random number
dummy_input=torch.randn(batch_size,3,224,224)# move model to gpu if available
model_transfer.to(device)# set eval mode
model_transfer.eval()# move input to gpu if available
dummy_input=dummy_input.to(device)# output using pytorch
torch_out=model_transfer(dummy_input)# print('torch_out', torch_out)
print('shape:',torch_out.shape)# export the model
torch.onnx.export(model_transfer,# model being run
dummy_input,# model input (or a tuple for multiple inputs)
'resnet101.onnx',# where to save the model (can be a file or file-like object)
input_names=['input_1'],# the model's input names
output_names=['output_1'],# the model's output names
dynamic_axes={'input_1':{0:'batch_size'},# variable length axes
'output_1':{0:'batch_size'}})print('Model exported successfully!')
# !pip install onnx onnxruntime-gpu
importonnx,onnxruntimemodel_name='resnet101.onnx'onnx_model=onnx.load(model_name)onnx.checker.check_model(onnx_model)ort_session=onnxruntime.InferenceSession(model_name)defto_numpy(tensor):returntensor.detach().cpu().numpy()iftensor.requires_gradelsetensor.cpu().numpy()# compute ONNX Runtime output prediction
ort_inputs={ort_session.get_inputs()[0].name:to_numpy(dummy_input)}ort_outs=ort_session.run(None,ort_inputs)# compare ONNX Runtime and PyTorch results
print('ort_outs[0]: ',ort_outs[0].shape)np.testing.assert_allclose(to_numpy(torch_out),ort_outs[0],rtol=1e-03,atol=1e-05)print("Exported model has been tested with ONNXRuntime, and the result looks good!")
Initialize the weights of a single linear layer from a uniform distribution.
Calculate cross-entropy loss for the following:
Note that cross_entropy or nll_loss in pytorch takes the raw inputs, not probabilites while calculating loss.
(4a).
Fix the below code to create a model having multiple linear layers:
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.linears = []
for i in range(5):
self.linears.append(nn.Linear(10, 10))
def forward(self, x):
for i, l in enumerate(self.linears):
x = self.linears[i // 2](x) + l(x)
return x
model = MyModule()
print(model)
Assignment 2
Use Transfer Learning to fine-tune the model on the following dataset and achieve validation classification accuracy of at least 0.85 (or validation loss 0.25) during training. (Choose pretrained model of your choice.)
Dataset: Flower images[Read more here]
Note: Don’t forget to normalize the data before training. You can also apply data augmentation, regularization, learning rate decay etc.
Special thanks to Udacity, where I started my PyTorch journey through PyTorch Scholarship and Deep Learning Nanodegree.
]]>Color and color spaces in Computer Vision2020-01-17T00:00:00+00:002020-01-17T00:00:00+00:00https://kharshit.github.io/blog/2020/01/17/color-and-color-spaces-in-computer-vision
The color we see is how our brain visually perceive the world. The color of an object is determined by the different wavelengths of light it reflects (and absorbs), which is affected by the object’s physical properties.
Color is a perception, not the physical property of an object … though it’s affected by the object’s properties.
Color space Vs Color model
In order to categorize and represent colors in computers, we use color models such as RGB that mathematically describe colors. On the other hand, a color space is the organization of colors that is used to display or reproduce colors in a medium such as computer screen. It’s how you map the real colors to the color model’s discrete values e.g. sRGB and Adobe RGB are two different color spaces, both based on the RGB color model i.e. RGB(16,69,201) may be differently displayed in sRGB and AdobeRGB. You can read more about it here.
Note that these terms are often used interchangeably.
Characteristics of color
The color can be characterized by the following properties:
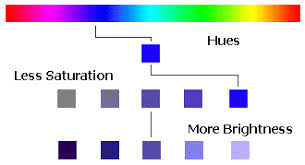
hue: the dominant color, name of the color itself e.g. red, yellow, green.
saturation or chroma: how pure is the color, the dominance of hue in color, purity, strength, intensity, intense vs dull.
brightness or value: how bright or illuminated the color is, black vs white, dark vs light.
Human eye
The human eye responds differently to different wavelengths of light. In fact, it is trichromatic – it contains three different types of photo-receptors called cones that are sensitive to different wavelengths of light. These are S-cones (short-wavelength), M-cones (middle-wavelength), and L-cones (long-wavelength) historically considered more sensitive to blue, green, and red light respectively.
The below graph shows the cone cells’ response to varying wavelengths of light.
As elucidated by the above figure, the peak value of L cone cells lies in greenish-yellow region, not red. Similarly, the S and M cones don’t directly correspond to blue and green color. In fact, the responsiveness of the cones to different colors varies from person-to-person.
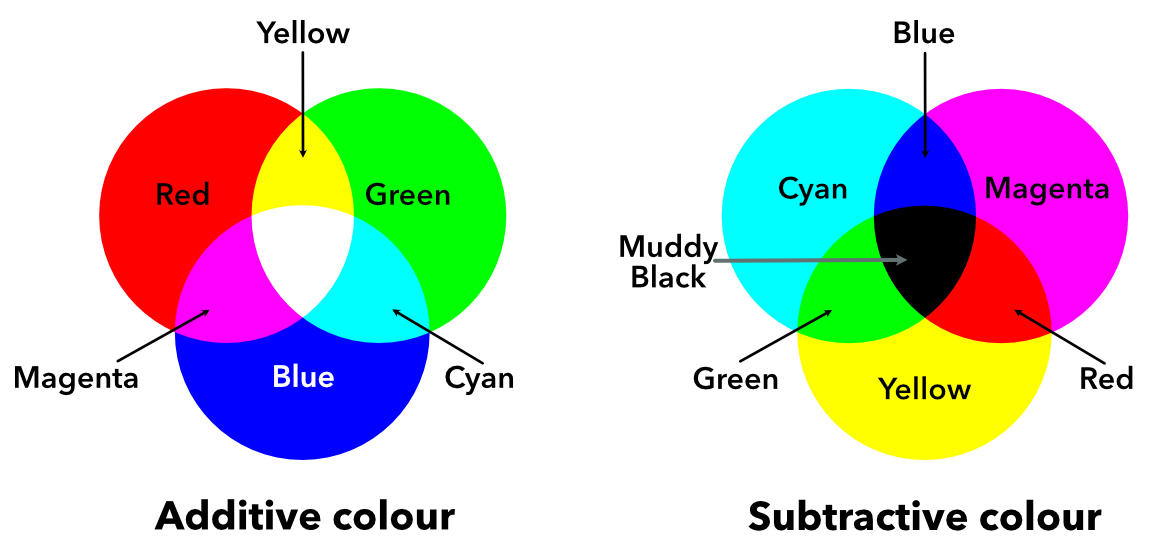
RGB
In RGB color model, all the colors are represented by adding the combinations of three primary colors; Red, Green, and Blue. All the primary colors at full intensity form white represented by RGB(255, 255, 255), and at zero intensity gives black (0, 0, 0).
Though RGB model is a convenient model for representing colors, it differs from how human eye perceive colors.
CYMK
Unlike RGB, CYMK is a subtractive color model i.e. the different colors are represented by subtracting some color from white e.g. cyan is white minus red. Cyan, magenta, and white are the complements of red, green and, blue respectively. The fourth black color is added to yield CYMK for better reproduction of colors.
Conversion from RGB to CMYK: C=1−R, M=1−G, Y=1−B.
HSV and HSL
HSV (Hue, Saturation, Value) and HSL (Hue, Saturation, Lightness) color models, developed by transforming the RGB color model, were designed to be more intuitive and interpretable. These are cylindrical representation of colors.
Hue, the color itself, ranges from 0 to 360 starting and ending with red. Saturation defines how pure the color is i.e. the dominance of hue in the color. It ranges from 0 (no color saturation) to 1 (full saturation). The Value (in HSV) and Lightness (in HSL), both ranging from 0 (no light, black) at the bottom to 1 (white) at the top, indicates the illumination level. They differ in the fact that full saturation is achieved at V=1 in HSV, while in HSL, it’s achieved at L=0.5.
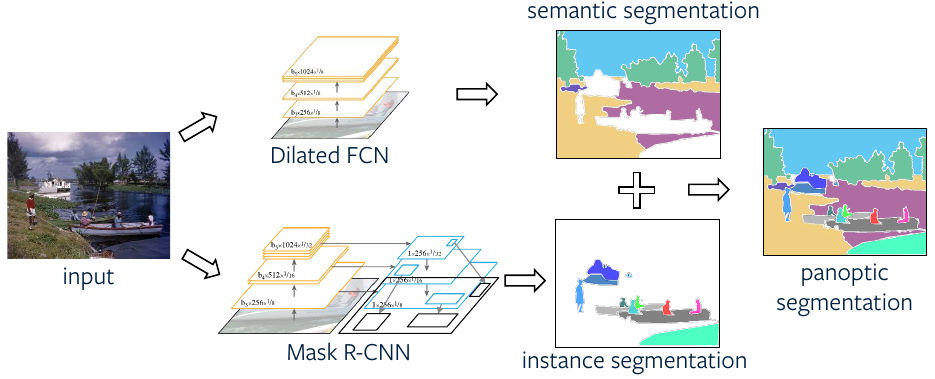
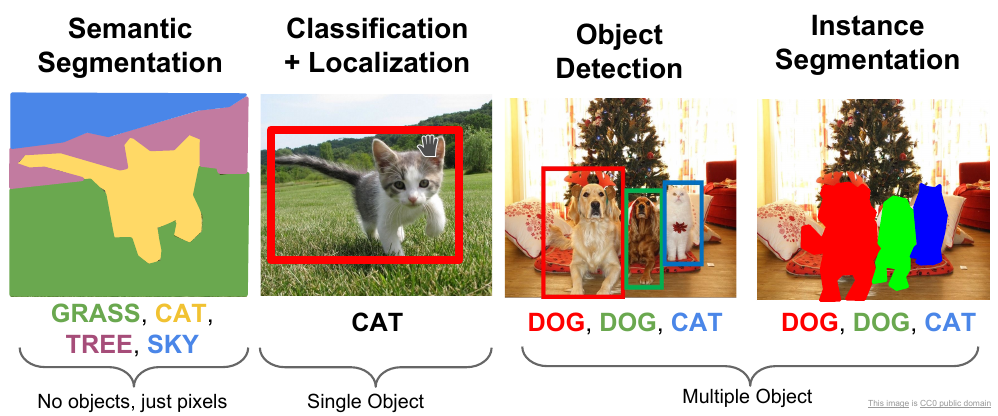
]]>Introduction to Panoptic Segmentation: A Tutorial2019-10-18T00:00:00+00:002019-10-18T00:00:00+00:00https://kharshit.github.io/blog/2019/10/18/introduction-to-panoptic-segmentation-tutorialIn semantic segmentation, the goal is to classify each pixel into the given classes. In instance segmentation, we care about segmentation of the instances of objects separately. The panoptic segmentation combines semantic and instance segmentation such that all pixels are assigned a class label and all object instances are uniquely segmented.
The goal in panoptic segmentation is to perform a unified segmentation task. In order to do so, let’s first understand few basic concepts.
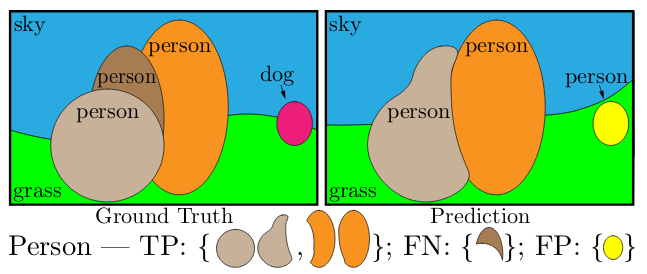
A thing is a countable object such as people, car, etc, thus it’s a category having instance-level annotation. The stuff is amorphous region of similar texture such as road, sky, etc, thus it’s a category without instance-level annotation. Studying thing comes under object detection and instance segmentation, while studying stuff comes under semantic segmentation.
The label encoding of pixels in panoptic segmentation involves assigning each pixel of an image two labels – one for semantic label, and other for instance id. The pixels having the same label are considered belonging to the same class, and instance id for stuff is ignored. Unlike instance segmentation, each pixel in panoptic segmentation has only one label corresponding to instance i.e. there are no overlapping instances.
For example, consider the following set of pixel values in a naive encoding manner:
26000, 260001, 260002, 260003, 19, 18
Here, pixel // 1000 gives the semantic label, and pixel % 1000 gives the instance id. Thus, the pixels 26000, 26001, 260002, 26003 corresponds to the same object and represents different instances. And, the pixels 19, and 18 represents the semantic labels belonging to the non-instance stuff classes.
In COCO, the panoptic annotations are stored in the following way:
Each annotation struct is a per-image annotation rather than a per-object annotation. Each per-image annotation has two parts: (1) a PNG that stores the class-agnostic image segmentation and (2) a JSON struct that stores the semantic information for each image segment.
annotation{"image_id":int,"file_name":str,# per-pixel segment ids are stored as a single PNG at annotation.file_name
"segments_info":[segment_info],}segment_info{"id":int,# unique segment id for each segment whether stuff or thing
"category_id":int,# gives the semantic category
"area":int,"bbox":[x,y,width,height],"iscrowd":0or1,# indicates whether segment encompasses a group of objects (relevant for thing categories only).
}categories[{"id":int,"name":str,"supercategory":str,"isthing":0or1,# stuff or thing
"color":[R,G,B],}]
In semantic segmentation, IoU and per-pixel accuracy is used as a evaluation criterion. In instance segmentation, average precision over different IoU thresholds is used for evaluation. For panoptic segmentation, a combination of IoU and AP can be used, but it causes asymmetry for classes with or without instance-level annotations. That is why, a new metric that treats all the categories equally, called Panoptic Quality (PQ), is used.
As in the calculation of AP, PQ is also first calculated independently for each class, then averaged over all classes. It involves two steps: matching, and calculation.
Step 1 (matching): The predicted and ground truth segments are considered to be matched if their IoU > 0.5. It, with non-overlapping instances property, results in a unique matching i.e. there can be at most one predicted segment corresponding to a ground truth segment.
Step 2 (calculation): Mathematically, for a ground truth segment g, and for predicted segment p, PQ is calculated as follows.
Here, in the first equation, the numerator divided by TP is simply the average IoU of matched segments, and FP and FN are added to penalize the non-matched segments. As shown in the second equation, PQ can divided into segmentation quality (SQ), and recognition quality (RQ). SQ, here, is the average IoU of matched segments, and RQ is the F1 score.
Model
One of the ways to solve the problem of panoptic segmentation is to combine the predictions from semantic and instance segmentation models, e.g. Fully Convolutional Network (FCN) and Mask R-CNN, to get panoptic predictions. In order to do so, the overlapping instance predictions are first need to be converted to non-overlapping ones using a NMS-like (Non-max suppression) procedure.
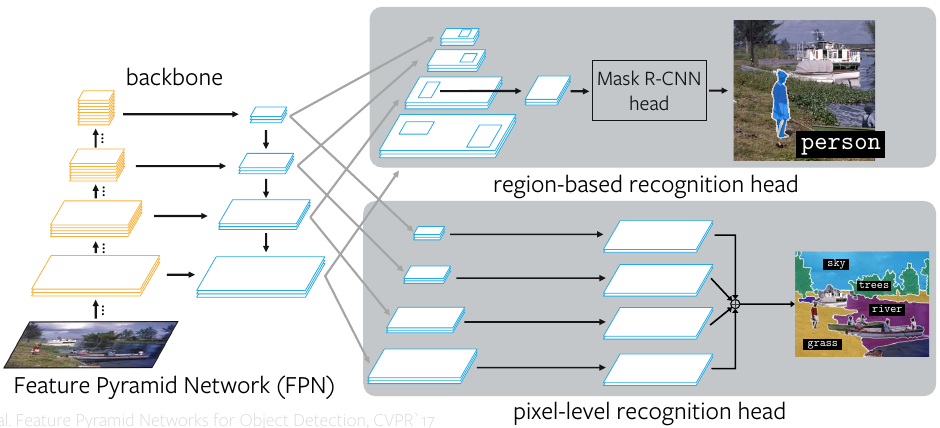
A better way is to use a unified Panoptic FPN (Feature Pyramid Network) framework. The idea is to use FPN for multi-level feature extraction as backbone, which is to be used for region-based instance segmentation as in case of Mask R-CNN, and add a parallel dense-prediction branch on top of same FPN features to perform semantic segmentation.
During training, the instance segmentation branch has three losses \(L_{cls}\) (classification loss), \(L_{bbox}\) (bounding-box loss), and \(L_{mask}\) (mask loss). The semantic segmentation branch has semantic loss, \(L_s\), computed as the per-pixel cross-entropy between the predicted and the ground truth labels.
In addition, a weighted combination of the semantic and instance loss is used by adding two tuning parameters \(\lambda_i\) and \(\lambda_s\) to get the panoptic loss.
Implementation
Facebook AI Research recently released Detectron2 written in PyTorch. In order to test panoptic segmentation using Mask R-CNN FPN, follow the below steps.
# install pytorch (https://pytorch.org) and opencv
pip install opencv-python
# install dependencies
pip install cython; pip install'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'# install detectron2
git clone https://github.com/facebookresearch/detectron2.git
cd detectron2
python setup.py build develop
# test on an image (using `MODEL.DEVICE cpu` for inference on CPU)
python demo/demo.py --config-file configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml --input ~/Pictures/image.jpg --opts MODEL.WEIGHTS detectron2://COCO-PanopticSegmentation/panoptic_fpn_R_50_3x/139514569/model_final_c10459.pkl MODEL.DEVICE cpu
]]>Evaluation metrics for object detection and segmentation: mAP2019-09-20T00:00:00+00:002019-09-20T00:00:00+00:00https://kharshit.github.io/blog/2019/09/20/evaluation-metrics-for-object-detection-and-segmentationRead about semantic segmentation, and instance segmentation.
The different evaluation metrics are used for different datasets/competitions. Most common are Pascal VOC metric and MS COCO evaluation metric.
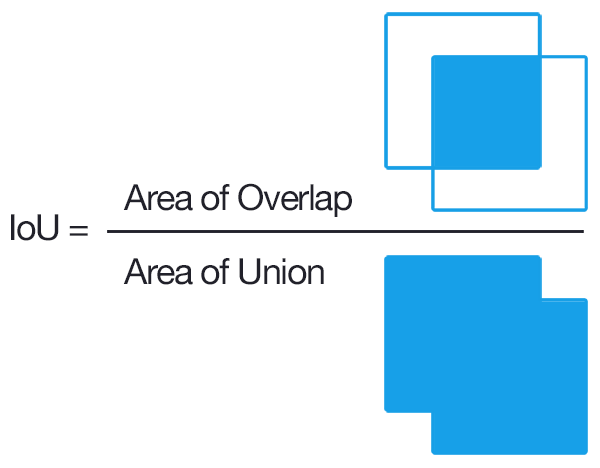
IoU (Intersection over Union)
To decide whether a prediction is correct w.r.t to an object or not, IoU or Jaccard Index is used. It is defines as the intersection b/w the predicted bbox and actual bbox divided by their union. A prediction is considered to be True Positive if IoU > threshold, and False Positive if IoU < threshold.
Precision and Recall
To understand mAP, let’s go through precision and recall first. Recall is the True Positive Rate i.e. Of all the actual positives, how many are True positives predictions. Precision is the Positive prediction value i.e. Of all the positive predictions, how many are True positives predictions. Read more in evaluation metrics for classification.
In order to calculate mAP, first, you need to calculate AP per class.
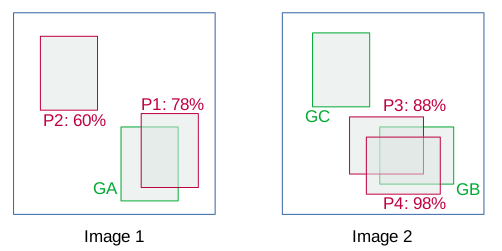
Consider the below images containing ground truths (in green) and bbox predictions (in red) for a particular class.
The details of the bboxes are as follows:
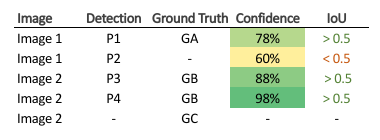
In this example, TP is considered if IoU > 0.5 else FP. Now, sort the images based on the confidence score. Note that if there are more than one detection for a single object, the detection having highest IoU is considered as TP, rest as FP e.g. in image 2.
In VOC metric, Recall is defined as the proportion of all positive examples ranked above a given rank. Precision is the proportion of all examples above that rank which are from the positive class.
Thus, in the column Acc (accumulated) TP, write the total number of TP encountered from the top, and do the same for Acc FP. Now, calculate the precision and recall e.g. for P4, Precision = 1/(1+0) = 1, and Recall = 1/3 = 0.33.
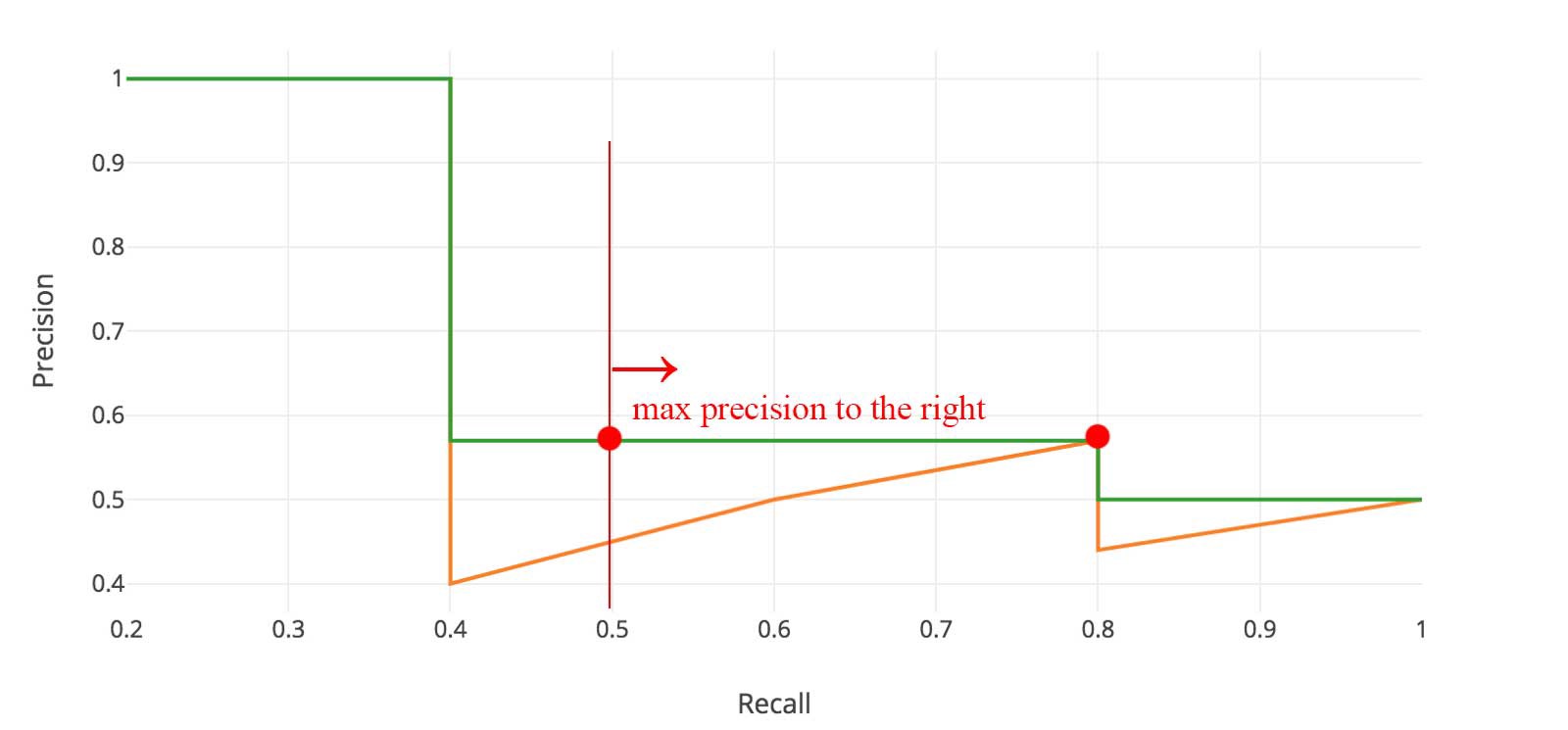
These precision and recall values are then plotted to get a PR (precision-recall) curve. The area under the PR curve is called Average Precision (AP). The PR curve follows a kind of zig-zag pattern as recall increases absolutely, while precision decreases overall with sporadic rises.
The AP summarizes the shape of the precision-recall curve, and, in VOC 2007, it is defined as the mean of precision values at a set of 11 equally spaced recall levels [0,0.1,…,1] (0 to 1 at step size of 0.1), not the AUC.
The precision at each recall level r is interpolated by taking the maximum precision measured for a method for which the corresponding recall exceeds r.
i.e. take the max precision value to the right at 11 equally spaced recall points [0: 0.1: 1], and take their mean to get AP.
However, from VOC 2010, the computation of AP changed.
Compute a version of the measured precision-recall curve with precision monotonically decreasing, by setting the precision for recall r to the maximum precision obtained for any recall \(\tilde{r}\geq r\). Then compute the AP as the area under this curve by numerical integration.
i.e. given the PR curve in orange, calculate the max precision to the right for all the recall points thus getting a new curve in green. Now, take the AUC using integration under the green curve. It would be the AP. The only difference from VOC 2007 here is that we’re taking not just 11 but all the points into account.
Now, we have AP per class (object category), mean Average Precision (mAP) is the averaged AP over all the object categories.
For the segmentation challenge in VOC, the segmentation accuracy (per-pixel accuracy calculated using IoU) is used as the evaluation criterion, which is defined as follows:
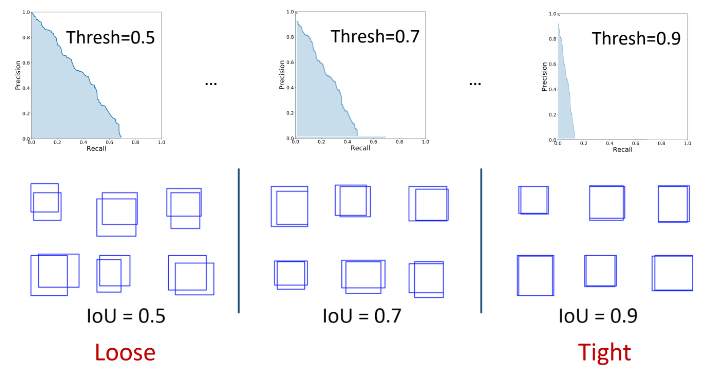
Usually, as in VOC, a prediction with IoU > 0.5 is considered as True Positive prediction. It means that two predictions of IoU 0.6 and 0.9 would have equal weightage. Thus, a certain threshold introduces a bias in the evaluation metric. One way to solve this problem is to use a range of IoU threshold values, and calculate mAP for each IoU, and take their average to get the final mAP.
Note that COCO uses [0:.01:1] R=101 recall thresholds for evaluation.
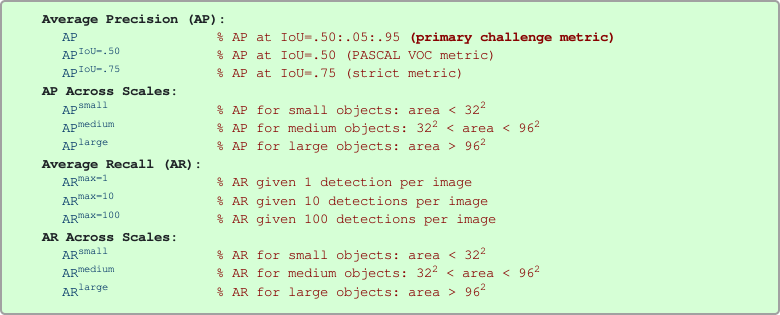
In COCO evaluation, the IoU threshold ranges from 0.5 to 0.95 with a step size of 0.05 represented as AP@[.5:.05:.95].
The AP at fixed IoUs such as IoU=0.5 and IoU=0.75 is written as AP50 and AP75 respectively.
Unless otherwise specified, AP and AR are averaged over multiple Intersection over Union (IoU) values. Specifically we use 10 IoU thresholds of .50:.05:.95. This is a break from tradition, where AP is computed at a single IoU of .50 (which corresponds to our metric \(AP^{IoU=.50}\)). Averaging over IoUs rewards detectors with better localization.
AP is averaged over all categories. Traditionally, this is called “mean average precision” (mAP). We make no distinction between AP and mAP (and likewise AR and mAR) and assume the difference is clear from context.
Two minute additions: Usually, the averages are taken in a different order (the final result is same), and in COCO, mAP is also referred to as AP i.e.
Step 1: For each class, calculate AP at different IoU thresholds and take their average to get the AP of that class.
]]>Quick intro to Instance segmentation: Mask R-CNN2019-08-23T00:00:00+00:002019-08-23T00:00:00+00:00https://kharshit.github.io/blog/2019/08/23/quick-intro-to-instance-segmentationThis is the third post in the Quick intro series: object detection (I), semantic segmentation (II).
“Boxes are stupid anyway though, I’m probably a true believer in masks except I can’t get YOLO to learn them.”
— Joseph Redmon, YOLOv3
The instance segmentation combines object detection, where the goal is to classify individual objects and localize them using a bounding box, and semantic segmentation, where the goal is to classify each pixel into the given classes. In instance segmentation, we care about detection and segmentation of the instances of objects separately.
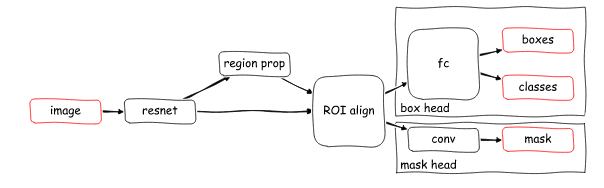
Mask R-CNN
Mask R-CNN is a state-of-the-art model for instance segmentation. It extends Faster R-CNN, the model used for object detection, by adding a parallel branch for predicting segmentation masks.
Before getting into Mask R-CNN, let’s take a look at Faster R-CNN.
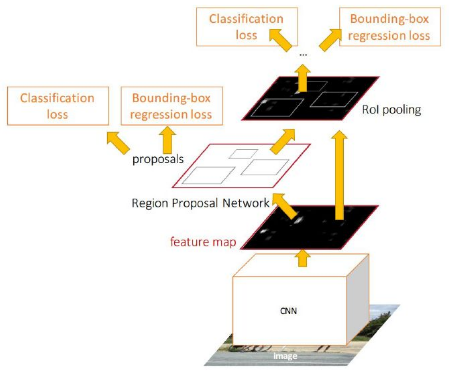
Faster R-CNN
Faster R-CNN consists of two stages.
Stage I
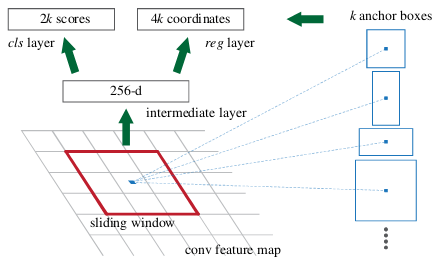
The first stage is a deep convolutional network with Region Proposal Network (RPN), which proposes regions of interest (ROI) from the feature maps output by the convolutional neural network i.e.
The input image is fed into a CNN, often called backbone, which is usually a pretrained network such as ResNet101. The classification (fully connected) layers from the backbone network are removed so as to use it as a feature extractor. This also makes the network fully convolutional, thus it can take any input size image.
The RPN uses a sliding window method to get relevant anchor boxes (the precalculated fixed sized bounding boxes having different sizes that are placed throughout the image that represent the approximate bbox predictions so as to save the time to search) from the feature maps.
It then does a binary classification that the anchor has object or not (into classes fg or bg), and bounding box regression to refine bounding boxes. The anchor is classified as positive label (fg class) if the anchor(s) has highest Intersection-over-Union (IoU) with the ground truth box, or, it has IoU overlap greater than 0.7 with the ground truth.
At each sliding window location, a number of proposals (max k) are predicted corresponding to anchor boxes. So the reg layer has 4k outputs encoding the coordinates of k boxes, and the cls layer outputs 2k scores that estimate probability of object or not object for each proposal.
In Faster R-CNN, k=9 anchors representing 3 scales and 3 aspect ratios of anchor boxes are present at each sliding window position. Thus, for a convolutional feature map of a size W×H(typically∼2,400), there are WHk anchors in total.
Hence, at this stage, there are two losses i.e. bbox binary classification loss, \(L_{cls_1}\) and bbox regression loss, \(L_{bbox_1}\).
The top (positive) anchors output by the RPN, called proposals or Region of Interest (RoI) are fed to the next stage.
Stage II
The second stage is essentially Fast R-CNN, which using RoI pooling layer, extracts feature maps from each RoI, and performs classification and bounding box regression. The RoI pooling layer converts the section of feature map corresponding to each (variable sized) RoI into fixed size to be fed into a fully connected layer.
For example, say, for a 8x8 feature map, the RoI is 7x5 in the bottom left corner, and the RoI pooling layer outputs a fixed size 2x2 feature map. Then, the following operations would be performed:
Divide the RoI into 2x2.
Perform max-pooling i.e. take maximum value from each section.
The fc layer further performs softmax classification of objects into classes (e.g. car, person, bg), and the same bounding box regression to refine bounding boxes.
Thus, at the second stage as well, there are two losses i.e. object classification loss (into multiple classes), \(L_{cls_2}\), and bbox regression loss, \(L_{bbox_2}\).
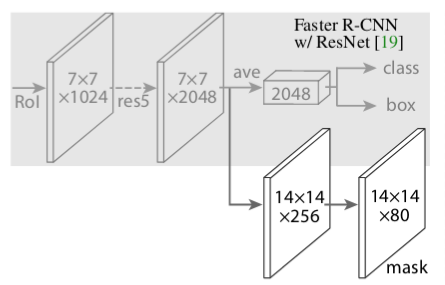
Mask prediction
Mask R-CNN has the identical first stage, and in second stage, it also predicts binary mask in addition to class score and bbox. The mask branch takes positive RoI and predicts mask using a fully convolutional network (FCN).
In simple terms, Mask R-CNN = Faster R-CNN + FCN
Finally, the loss function is
\[L = L_{cls} + L_{bbox} + L_{mask}\]
The \(L_{cls} (L_{cls_1} + L_{cls_2})\) is the classification loss, which tells how close the predictions are to the true class, and \(L_{bbox} (L_{bbox_1} + L_{bbox_2})\) is the bounding box loss, which tells how good the model is at localization, as discussed above. In addition, there is also \(L_{mask}\), loss for mask prediction, which is calculated by taking the binary cross-entropy between the predicted mask and the ground truth. This loss penalizes wrong per-pixel binary classifications (fg/bg w.r.t ground truth label).
Mask R-CNN encodes a binary mask per class for each of the RoIs, and the mask loss for a specific RoI is calculated based only on the mask corresponding to its true class, which prevents the mask loss from being affected by class predictions.
The mask branch has a \(Km^2\)-dimensional output for each RoI, which encodes K binary masks of resolution m×m, one for each of the K classes. To this we apply a per-pixel sigmoid, and define \(L_{mask}\) as the average binary cross-entropy loss.
In total, there are five losses as follows:
rpn_class_loss, \(L_{cls_1}\): RPN (bbox) anchor binary classifier loss
rpn_bbox_loss, \(L_{bbox_1}\): RPN bbox regression loss
fastrcnn_class_loss, \(L_{cls_2}\): loss for the classifier head of Mask R-CNN
fastrcnn_bbox_loss, \(L_{bbox_2}\): loss for Mask R-CNN bounding box refinement
maskrcnn_mask_loss, \(L_{mask}\): mask binary cross-entropy loss for the mask head
Other improvements
Feature Pyramid Network
Mask R-CNN also utilizes a more effective backbone network architecture called Feature Pyramid Network (FPN) along with ResNet, which results in better performance in terms of both accuracy and speed.
Faster R-CNN with an FPN backbone extracts RoI features from different levels of the feature pyramid according to their scale, but otherwise the rest of the approach is similar to vanilla ResNet.
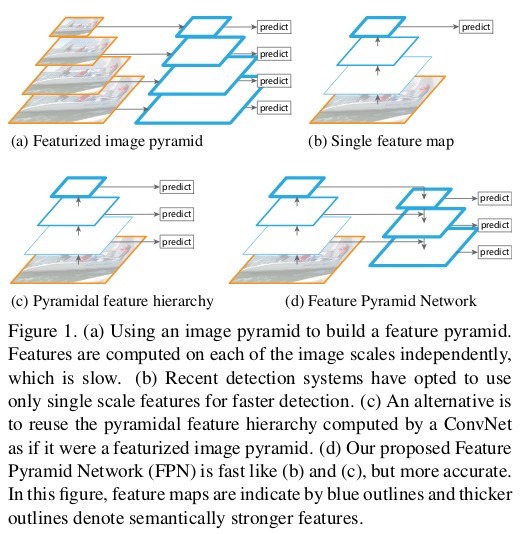
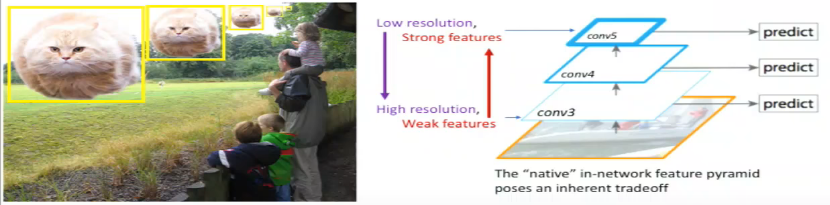
In order to detect object at different scales, various techniques have been proposed. One of them (c) utilizes the fact that deep CNN build a multi-scale representation of the feature maps. The features computed by various layers of the CNN acts as a feature pyramid. Here, you can use your model to detect objects at different levels of the pyramid thus allowing your model to detect object across a large range of scales e.g. the model can detect small objects at conv3 as it has higher spatial resolution thus allowing the model to extract better features for detection compared to detecting small objects at conv5, which has lower spatial resolution. But, an important thing to note here is that the quality of features at conv3 won’t be as good for classification as features at conv5.
The above idea is fast as it utilizes the inherent working of CNN by using the features extracted at different conv layers for multi-scale detection, but compromises with the feature quality.
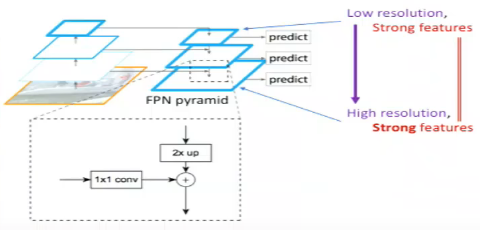
FPN uses the inherent multi-scale representation in the network as above, and solves the problem of weak features at later layers for multi-scale detection.
The forward pass of the CNN gives the feature maps at different conv layers i.e. builds the multi-level representation at different scales. In FPN, lateral connections are added at each level of the pyramid. The idea is to take top-down strong features (from conv5) and propagate them to the high resolution feature maps (to conv3) thus having strong features across all levels.
RoiAlign
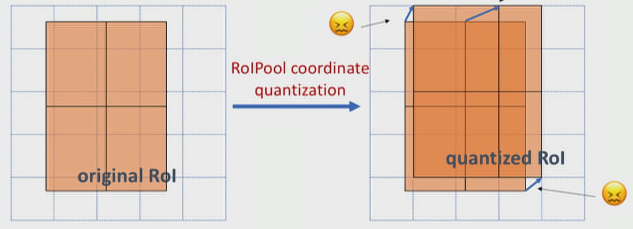
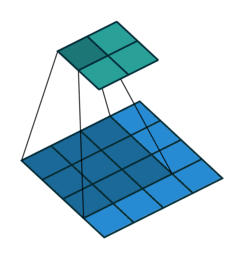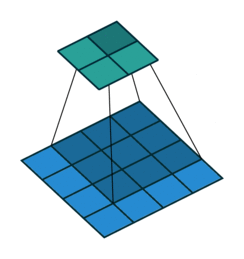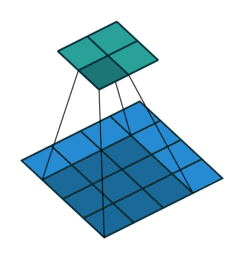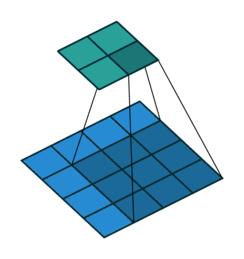
As discussed above, RoIPool layer extracts small feature maps from each RoI. The problem with RoIPool is quantization. If the RoI doesn’t perfectly align with the grid in feature map as shown, the quantization breaks pixel-to-pixel alignment. It isn’t much of a problem in object detection, but in case of predicting masks, which require finer spatial localization, it matters.
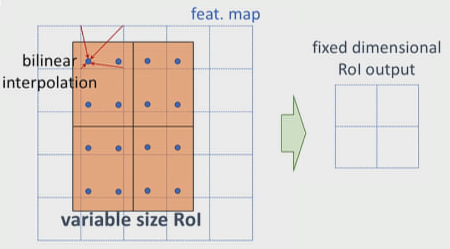
RoIAlign is an improvement over the RoIPool operation. What RoIAlign does is to smoothly transform features from the RoIs (which has different aspect sizes) into fixed size feature vectors without using quantization. It uses bilinear interpolation to do. A grid of sampling points are used within each bin of RoI, which are used to interpolate the features at its nearest neighbors as shown.
For example, in the above figure, you can’t apply the max-pooling directly due to the misalignment of RoI with the feature map grids, thus in case of RoIAlign, four points are sampled in each bin using bilinear interpolation from its nearest neighbors. Finally, the max value from these points is chosen to get the required 2x2 feature map.
# install dependencies
pip install ninja yacs cython matplotlib tqdm opencv-python
# install COCO API
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
python setup.py build_ext install
cd ../../
# install apexrm-rf apex
git clone https://github.com/NVIDIA/apex.git
cd apex
git pull
# if no GPU available, try installing removing --cuda_ext
python setup.py install--cuda_ext--cpp_extcd ../
# install maskrcnn-benchmark
git clone https://github.com/facebookresearch/maskrcnn-benchmark.git
cd maskrcnn-benchmark
# the following will install the lib with symbolic links, so that you can modify# the files if you want and won't need to re-build it
python setup.py build develop
# download predictor.py, which contains necessary utility functions
wget https://raw.githubusercontent.com/facebookresearch/maskrcnn-benchmark/master/demo/predictor.py
# download configuration file
wget https://raw.githubusercontent.com/facebookresearch/maskrcnn-benchmark/master/configs/caffe2/e2e_mask_rcnn_R_50_FPN_1x_caffe2.yaml
Here, for inference, we’ll use Mask R-CNN model pretrained on MS COCO dataset.
importnumpyasnpimportmatplotlib.pyplotaspltimportmatplotlib.pylabaspylabimportrequestsfromioimportBytesIOfromPILimportImagefrommaskrcnn_benchmark.configimportcfgfrompredictorimportCOCODemoconfig_file="e2e_mask_rcnn_R_50_FPN_1x_caffe2.yaml"# update the config options with the config file
cfg.merge_from_file(config_file)# a helper class `COCODemo`, which loads a model from the config file, and performs pre-processing, model prediction and post-processing for us
coco_demo=COCODemo(cfg,min_image_size=800,confidence_threshold=0.7,)pil_image=Image.open('cats.jpg').convert("RGB")# convert to BGR format
image=np.array(pil_image)[:,:,[2,1,0]]# compute predictions
predictions=coco_demo.run_on_opencv_image(image)# plot
f,ax=plt.subplots(1,2,figsize=(15,4))ax[0].set_title('input image')ax[0].axis('off')ax[0].imshow(pil_image)ax[1].set_title('segmented output')ax[1].axis('off')ax[1].imshow(predictions[:,:,[2,1,0]])plt.savefig("segmented_output.png",bbox_inches='tight')
Notice that, here, both the instances of cats are segmented separately, unlike semantic segmentation.
Other Instance segmentation models
MS R-CNN (Mask Scoring R-CNN)
In Mask R-CNN, the instance classification score is used as the mask quality score. However, it’s possible that due to certain factors such as background clutter, occlusion, etc. the classification score is high, but the mask quality (IoU b/w instance mask and ground truth) is low. MS R-CNN uses a network that learns the quality of mask. The mask score is reevaluated by multiplying the predicted MaskIoU and classification score.
Within the Mask R-CNN framework, we implement a MaskIoU prediction network named MaskIoU head. It takes both the output of themask head and RoI feature as input, and is trained using a simple regression loss.
i.e. MS R-CNN = Mask R-CNN + MaskIoU head module
YOLACT (You Only Look At CoefficienTs)
YOLACT is the current fastest instance segmentation method. It can achieve real-time instance segmentation results i.e. 30fps.
It breaks the instance segmentation process into two parts i.e. it generates a set of prototype masks in parallel with predicting per-instance mask coefficients. Then the prototypes are linearly combined with the mask coefficients to produce the instance masks.
]]>Quick intro to semantic segmentation: FCN, U-Net and DeepLab2019-08-09T00:00:00+00:002019-08-09T00:00:00+00:00https://kharshit.github.io/blog/2019/08/09/quick-intro-to-semantic-segmentationSuppose you’ve an image, consisting of cats. You want to classify every pixel of the image as cat or background. This process is called semantic segmentation.
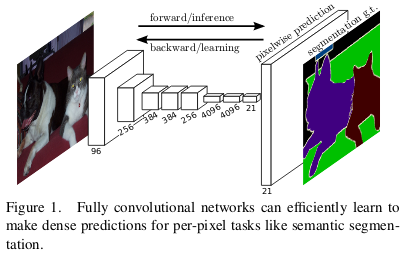
One of the ways to do so is to use a Fully Convolutional Network (FCN) i.e. you stack a bunch of convolutional layers in a encoder-decoder fashion. The encoder downsamples the image using strided convolution giving a compressed feature representation of the image, and the decoder upsamples the image using methods like transpose convolution to give the segmented output (Read more about downsampling and upsampling).
The fully connected (fc) layers of a convolutional neural network requires a fixed size input. Thus, if your model is trained on an image size of 224x224, the input image of size 227x227 will throw an error. The solution, as adapted in FCN, is to replace fc layers with 1x1 conv layers. Thus, FCN can perform semantic segmentation for any input size image.
In FCN, the skip connections from the earlier layers are also utilized to reconstruct accurate segmentation boundaries by learning back relevant features, which are lost during downsampling.
Semantic segmentation faces an inherent tension between semantics and location: global information resolves what while local information resolves where… Combining fine layers and coarse layers (by using skip connections) lets the model make local predictions that respect global structure.
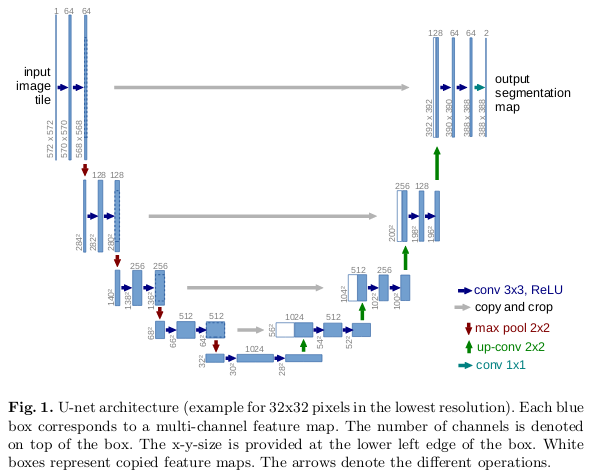
U-Net
The U-Net build upon the concept of FCN. Its architecture, similar to the above encoder-decoder architecture, can be divided into three parts:
The contracting or downsampling path consists of 4 blocks where each block applies two 3x3 convolution (+batch norm) followed by 2x2 max-pooling. The number of features maps are doubled at each pooling layer (after each block) as 64 -> 128 -> 256 and so on.
The horizontal bottleneck consists of two 3x3 convolution followed by 2x2 up-convolution.
The expanding or upsampling path, complimentary to the contracting path, also consists of 4 blocks, where each block consists of two 3x3 conv followed by 2x2 upsampling (transpose convolution). The number of features maps here are halved after every block.
The pretrained models such as resnet18 can be used as the left part of the model.
U-Net also has skip connections in order to localize, as shown in white. The upsampled output is concatenated with the corresponding cropped (cropped due to the loss of border pixels in every convolution) feature maps from the contracting path (the features learned during downsampling are used during upsampling).
Finally, the resultant output passes through 3x3 conv layer to provide the segmented output, where number of feature maps is equal to number segments desired.
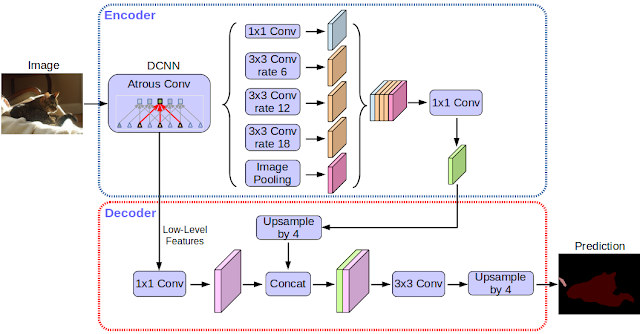
DeepLab
DeepLab is a state-of-the-art semantic segmentation model having encoder-decoder architecture. The encoder consisting of pretrained CNN model is used to get encoded feature maps of the input image, and the decoder reconstructs output, from the essential information extracted by encoder, using upsampling.
To understand the DeepLab architecture, let’s go through its fundamental building blocks one by one.
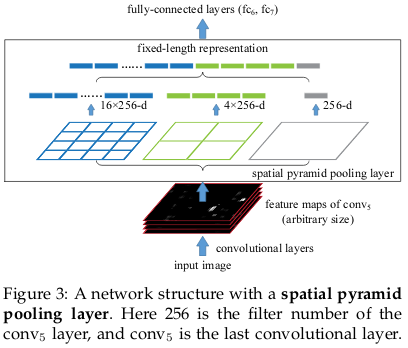
Spatial Pyramid Pooling
In order to deal with the different input image sizes, fc layers can be replaced by 1x1 conv layers as in case of FCN. But we want our model to be robust to different size of input images. The solution to deal with variable sized images is to train the model on various scales of the input image to capture multi-scale contextual information.
Usually, a single pooling layer is used between the last conv layer and fc layer. DeepLab, instead, utilizes a technique of using multiple pooling layer called Spatial Pyramid Pooling (SPP) to deal with multi-scale images. SPP divides the feature maps from the last conv layer into a fixed number of spatial bins having size proportional to the image size. Each bin gives a different scaled image as shown in the figure. The output of the SPP is a fixed size vector FxB, where F is the number of filters (feature maps) in the last conv layer, and B is the fixed number of bins. The different output vectors (16x256-d, 4x256-d, 1x256-d) are concatenated to form a fixed (4x4+2x2+1)x256=5376 dimension vector, which is fed into the fc layer.
There is a drawback to SPP that it leads to an increase in the computational complexity of the model, the solution to which is atrous convolution.
Dilated or atrous convolutions
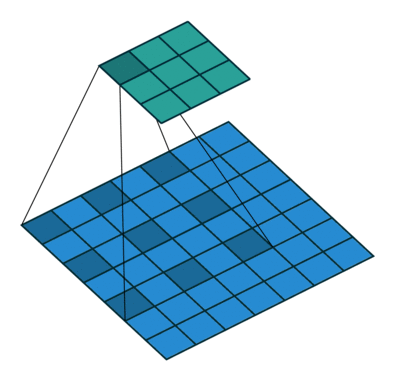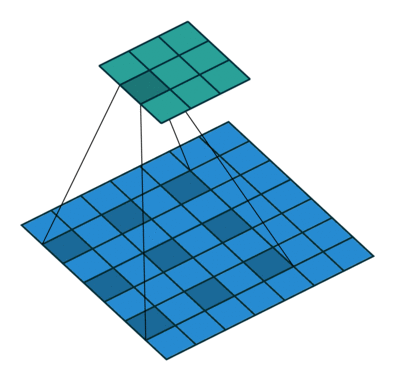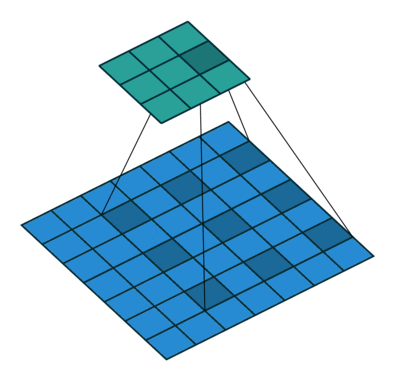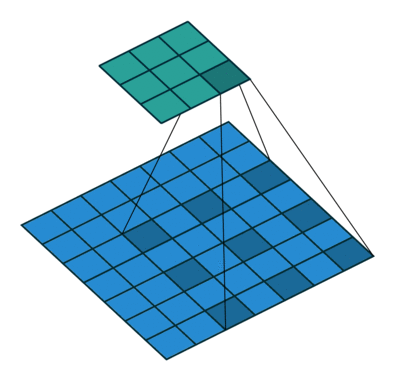
Unlike the normal convolution, dilation or atrous convolution has one more parameter called dilation or atrous rate, r, which defines the spacing between the values in a kernel. The dilation rate of 1 corresponds to the normal convolution. DeepLab uses atrous rates of 6, 12 and 18.
The benefit of this type of convolution is that it enlarges field of view of filters to incorporate larger context without increasing the number of parameters.
Deeplab uses atrous convolution with SPP called Atrous Spatial Pyramid Pooling (ASPP). In DeepLabv3+, depthwise separable convolutions are applied to both ASPP and decoder modules.
Depthwise separable convolutions
Suppose you’ve an input RGB image of size 12x12x3, the normal convolution operation using 5x5x3 filter without padding and stride of 1 gives the output of size 8x8x1. In order to increase the number of channels (e.g. to get output of 8x8x256), you’ll have to use 256 filters to create 256 8x8x1 outputs and stack them together to get 8x8x256 output i.e. 12x12x3 — (5x5x3x256) —> 12x12x256. This whole operations costs 256x5x5x3x8x8=1,228,800 multiplications.
The depthwise separable convolution dissolves the above into two steps:
In depthwise convolution, the convolution operation is perfomed separately for each channel using three 5x5x1 filter, stacking whose outputs gives 8x8x3 image.
The pointwise convolution is used to increase the depth, number of channels, by taking convolution of 256 1x1x3 filters with the 8x8x3 image, where each filter gives 8x8x1 image which are stacked together to get 8x8x256 desired output image.
The process can be described as 12x12x3 — (5x5x1x1) —> (1x1x3x256) —> 12x12x256. This whole operation took 3x5x5x8x8 + 256x1x1x3x8x8 = 53,952 multiplication, which is far less compared to that of normal convolution.
DeepLabv3+ uses xception (pointwise conv is followed by depthwise conv) as the feature extractor in the encoder portion. The depthwise separable convolutions are applied in place of max-pooling. The encoder uses output stride of 16, while in decoder, the encoded features by the encoder are first upsampled by 4, then concatenated with corresponding features from the encoder, then upsampled again to give output segmentation map.
Let’s test the DeepLabv3 model, which uses resnet101 as its backbone, pretrained on MS COCO dataset, in PyTorch.
importtorchfromtorchvisionimporttransformsimportPIL.Imageimportmatplotlib.pyplotasplt# load deeplab
model=torch.hub.load('pytorch/vision','deeplabv3_resnet101',pretrained=True)model.eval()# load the input image and preprocess
input_image=PIL.Image.open('image.png')preprocess=transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225]),])input_tensor=preprocess(input_image)input_batch=input_tensor.unsqueeze(0)# move the input and model to GPU if available
iftorch.cuda.is_available():input_batch=input_batch.to('cuda')model.to('cuda')withtorch.no_grad():output=model(input_batch)['out'][0]output_predictions=output.argmax(0)# create a color pallette, selecting a color for each class
palette=torch.tensor([2**25-1,2**15-1,2**21-1])colors=torch.as_tensor([iforiinrange(21)])[:,None]*palettecolors=(colors%255).numpy().astype("uint8")# plot the semantic segmentation predictions
r=PIL.Image.fromarray(output_predictions.byte().cpu().numpy()).resize(input_image.size)r.putpalette(colors)f,ax=plt.subplots(1,2,figsize=(15,4))ax[0].set_title('input image')ax[0].axis('off')ax[0].imshow(input_image)ax[1].set_title('segmented output')ax[1].axis('off')ax[1].imshow(r)plt.savefig("segmented_output.png",bbox_inches='tight')# plt.show()
]]>Converting FC layers to CONV layers2019-08-02T00:00:00+00:002019-08-02T00:00:00+00:00https://kharshit.github.io/blog/2019/08/02/converting-fc-layers-to-conv-layers
It is worth noting that the only difference between FC and CONV layers is that the neurons in the CONV layer are connected only to a local region in the input, and that many of the neurons in a CONV volume share parameters.
Suppose, the 7x7x512 activation volume output of the conv layer is fed into a 4096 sized fc layer. This fc layer can be replaced with a conv layer having 4096 filters (kernel) of size 7x7x512, where each filter gives 1x1x1 output which are concatenated to give output of 1x1x4096, which is equal to what we get in fc layer.
As a general rule, replace K sized fc layer with a conv layer having K number of filters of the same size that is input to the fc layer.
For example, if a conv1 layer outputs HxWxC volume, and it’s fed to a K sized fc layer. Then, the fc layer can be replaced with a conv2 layer having K HxW filters. In PyTorch, it’d be
Using the above reasoning, you’d notice that all the further fc layers, except the first one, will require 1x1 convolutions as shown in the above example, it’s because after the first conv layer, the feature maps are of size 1x1xC where C is the number of channels.
]]>Two Years of Technical Fridays2019-07-19T00:00:00+00:002019-07-19T00:00:00+00:00https://kharshit.github.io/blog/2019/07/19/two-years-of-technical-fridays
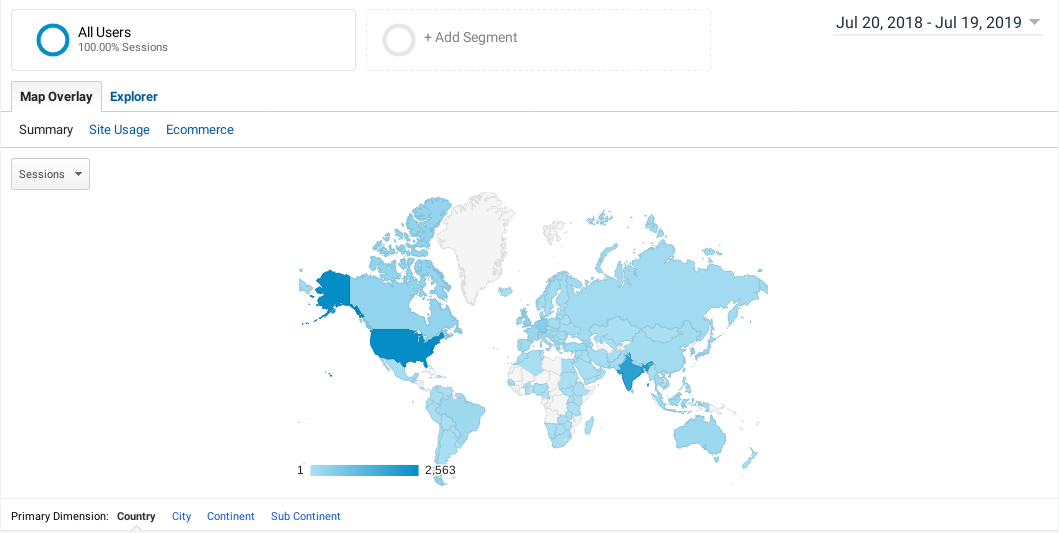
In the last year (July 20, 2018 - July 19, 2019), the site had 10,099 users from all over the world. That’s an incredible achievement. Thank you all :)
For the past few months, I’ve been working mainly in the field of Computer Vision, so I expect to write more blog posts related to it. Once again, thank you to all the readers, it has been an incredible journey so far, and I hope to continue writing on some of the amazing topics in the future.
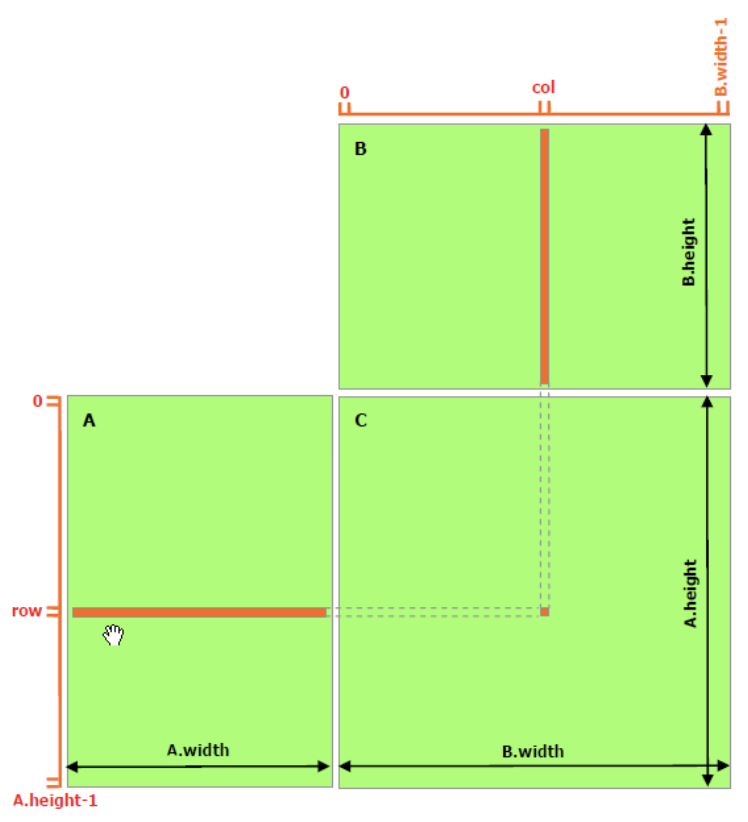
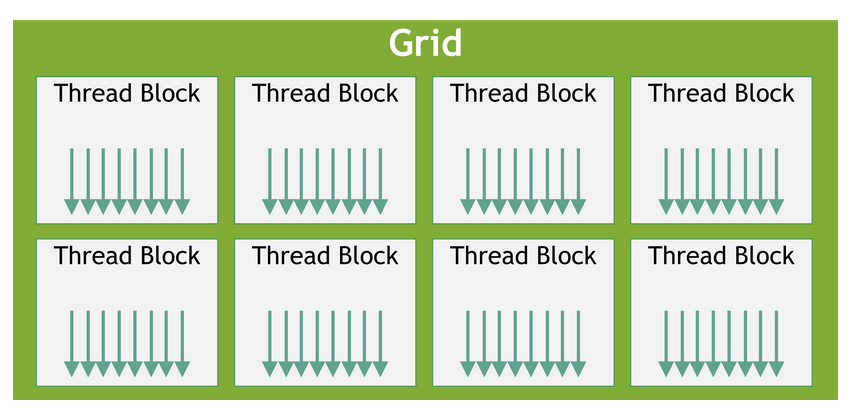
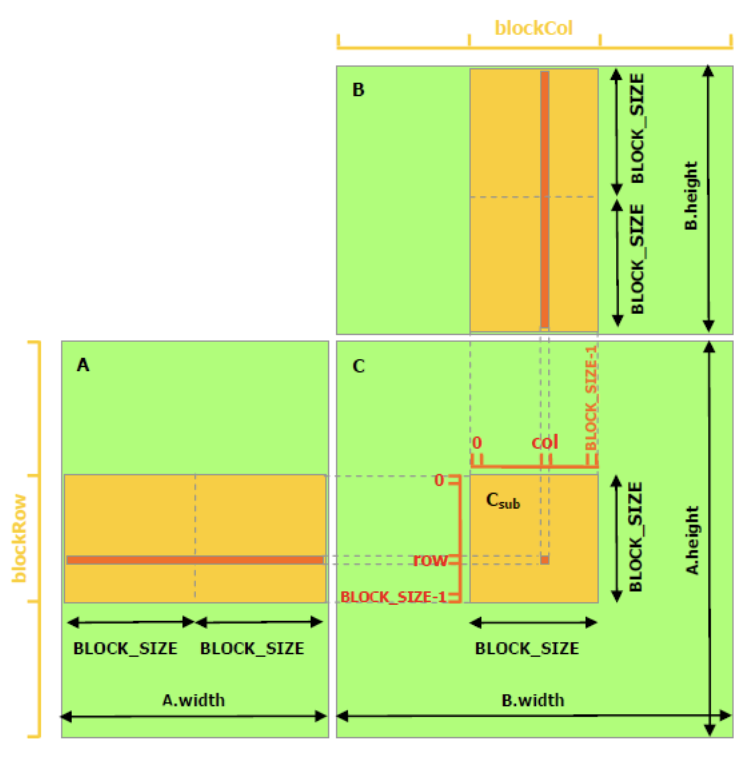


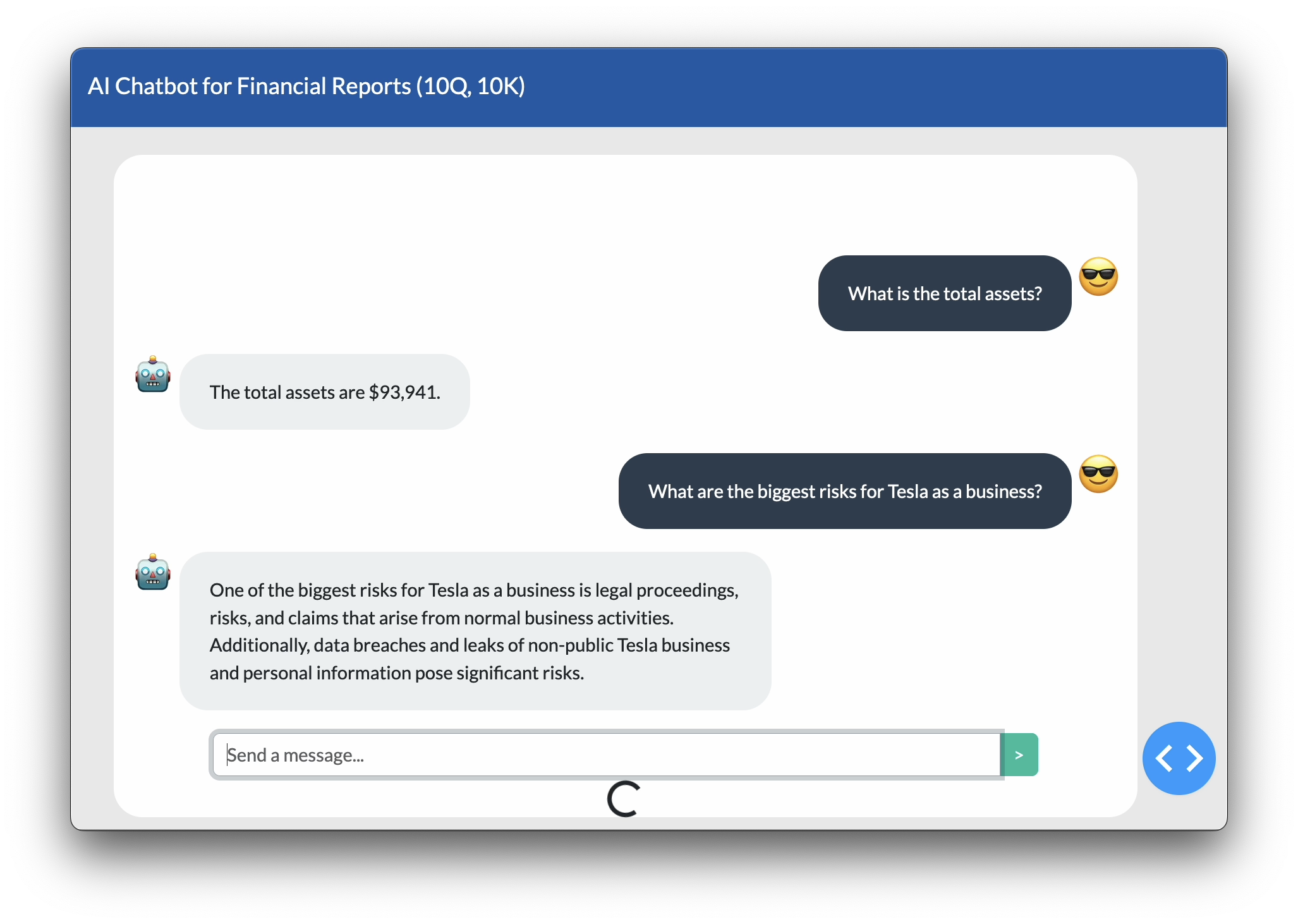
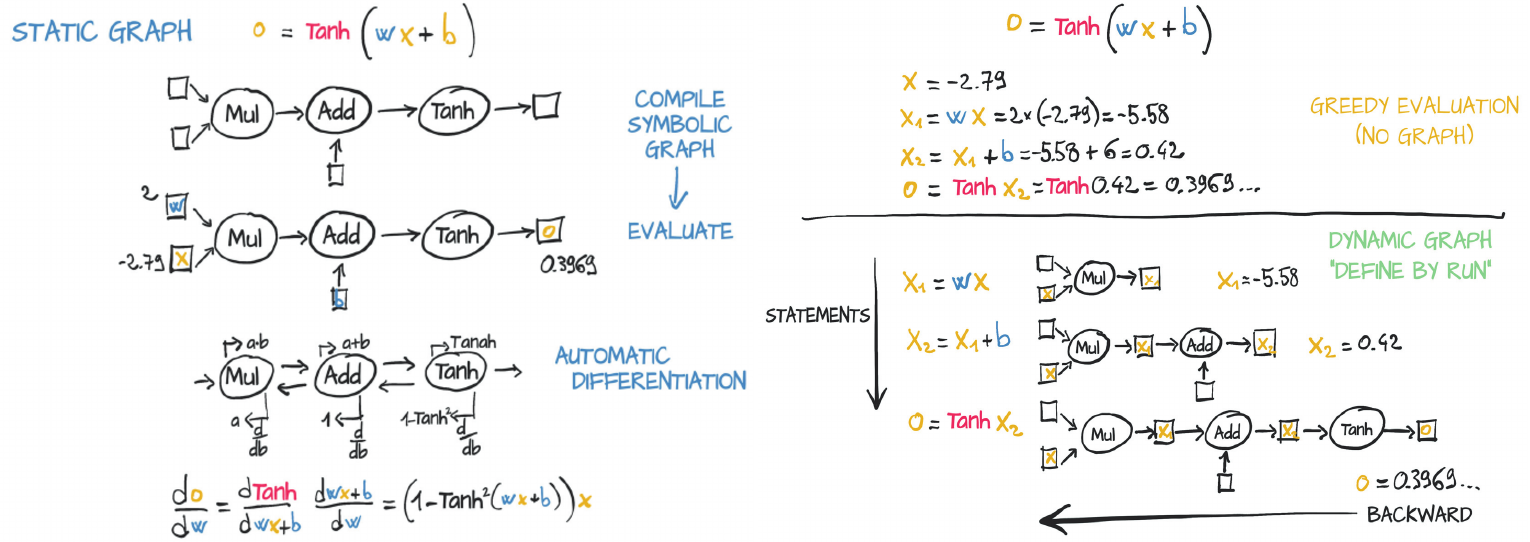
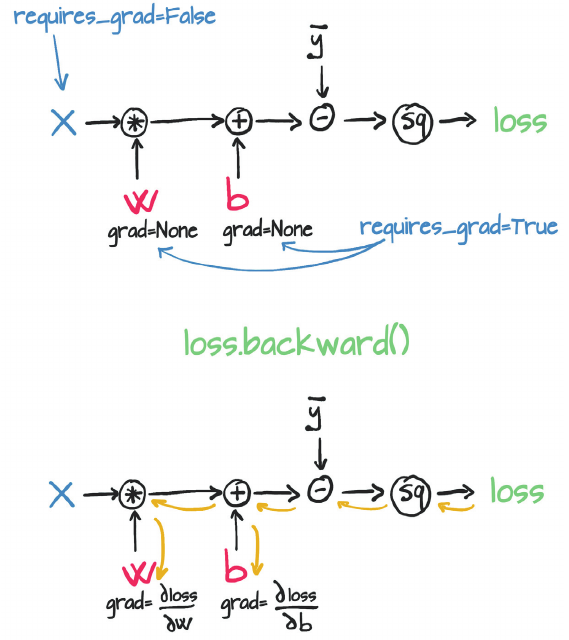
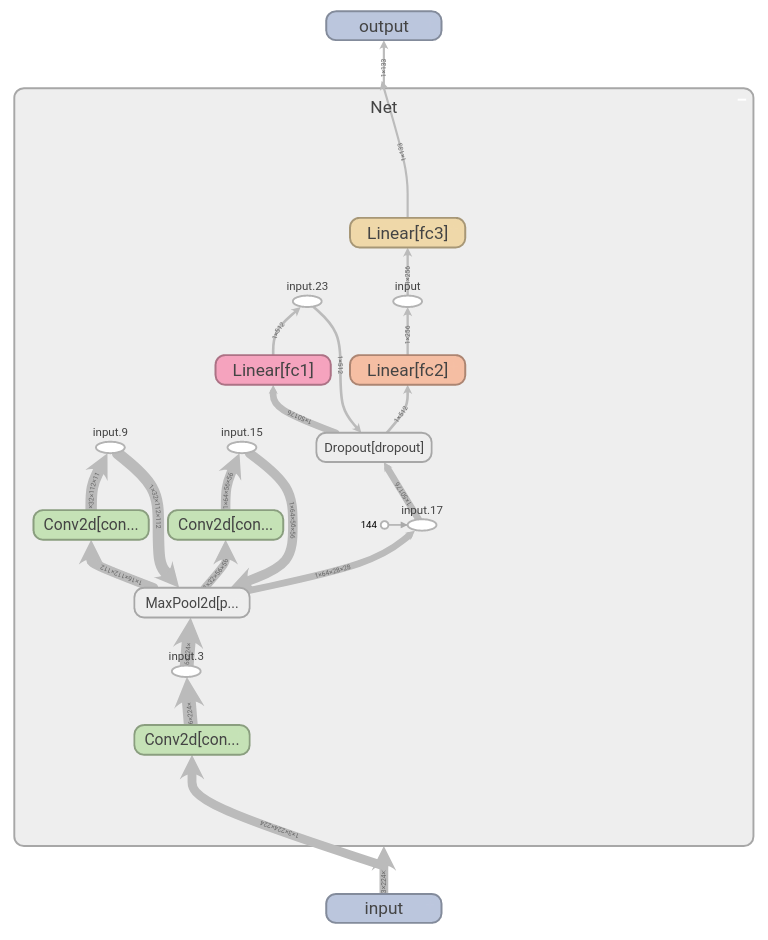

 Photo by
Photo by